“Link Prediction of Weighted Triples for Knowledge Graph Completion Within the Scholarly Domain” is a journal paper accepted at IEEE Access Mojtaba Nayyeri1,2, Gökce Müge Cil1, Sahar Vahdati2, Francesco Osborne3, Andrey Kravchenko4, Simone Angioni5, Angelo Salatino3, Diego Reforgiato Recupero5, Enrico Motta3, Jens Lehmann1,6 1 SDA Research Group, University of Bonn, 53115 Bonn, Germany 2 […]
Category: Graph Analysis

Trans4E: Link Prediction on Scholarly Knowledge Graphs
“Trans4E: Link Prediction on Scholarly Knowledge Graphs” is a journal paper submitted to the Special Issue on “Knowledge Graph Representation & Reasoning” at the Neurocomputing Journal Mojtaba Nayyeria, Gokce Muge Cila, Sahar Vahdatib, Francesco Osborned, Mahfuzur Rahmana,Simone Angionie, Angelo Salatinod, Diego Reforgiato Recuperoe, Nadezhda Vassilyevaa, Enrico Mottad and Jens Lehmanna,c aSDA Research Group, University […]

Applying Machine Learning Techniques to Big Data in the Scholarly Domain
Ontologies of research areas have been proven to be useful in many application for analysing and making sense of scholarly data. In this lecture, I will present how we produced the Computer Science Ontology (CSO), which is the largest ontology of research areas in the field of Computer Science, and discuss a number of applications that build on CSO, to support high-level tasks, such as topic classification, research trends forecasting, metadata extraction, and recommendation of books.

The AIDA Dashboard: Analysing Conferences with Semantic Technologies
“The AIDA Dashboard: Analysing Conferences with Semantic Technologies” is a demo paper submitted to the Posters and Demos tracks of the 19th International Semantic Web Conference. Simone Angioni1, Francesco Osborne2, Angelo A. Salatino2, Diego Reforgiato Recupero1, Enrico Motta2 1 University of Cagliari, Via Università 40, 09124 Cagliari 2 Knowledge Media Institute, The Open University, […]

Integrating Knowledge Graphs for Analysing Academia and Industry Dynamics
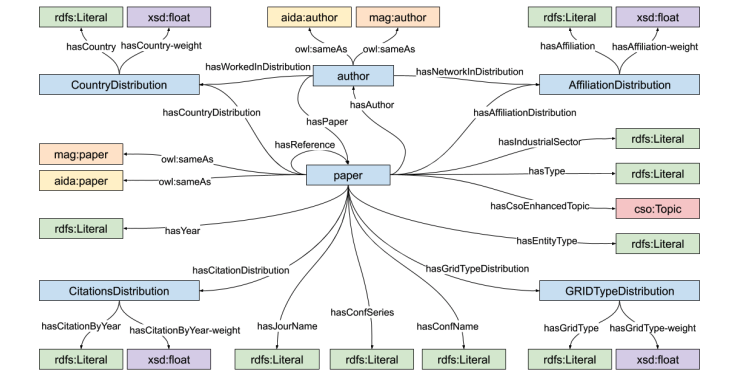
Academia and industry are constantly engaged in a joint effort for producing scientific knowledge that will shape the society of the future. Analysing the knowledge flow between them and understanding how they influence each other is a critical task for researchers, governments, funding bodies, investors, and companies. However, current corpora are unfit to support large-scale analysis of the knowledge flow between academia and industry since they lack of a good characterization of research topics and industrial sectors. In this short paper, we introduce the Academia/Industry DynAmics (AIDA) Knowledge Graph, which characterizes 14M papers and 8M patents according to the research topics drawn from the Computer Science Ontology. 4M papers and 5M patents are also classified according to the type of the author’s affiliations (academy, industry, or collaborative) and 66 industrial sectors (e.g., automotive, financial, energy, electronics) obtained from DBpedia. AIDA was generated by an automatic pipeline that integrates several knowledge graphs and bibliographic corpora, including Microsoft Academic Graph, Dimensions, English DBpedia, the Computer Science Ontology, and the Global Research Identifier Database.
1st Workshop on Scientific Knowledge Graphs (SKG2020)
In the last decade, we experienced an urgent need for a flexible, context-sensitive, fine-grained, and machine-actionable representation of scholarly knowledge and corresponding infrastructures for knowledge curation, publishing and processing. Such technical infrastructures are becoming increasingly popular in representing scholarly knowledge as structured, interlinked, and semantically rich Scholarly Knowledge Graphs (SKG).
The 1st Workshop on Scientific Knowledge Graphs (SKG2020) aims at bringing together researchers and practitioners from different fields (including, but not limited to, Digital Libraries, Information Extraction, Machine Learning, Semantic Web, Knowledge Engineering, Natural Language Processing, Scholarly Communication, and Bibliometrics) in order to explore innovative solutions and ideas for the production and consumption of Scientific Knowledge Graphs (SKGs).
Computer Science Ontology
The Computer Science Ontology is a large-scale ontology of research areas that was automatically generated using the Klink-2 algorithm on a dataset of about 16 million publications, mainly in the field of Computer Science. In the rest of the paper, we will refer to this corpus as the Rexplore dataset.
The current version of CSO includes 14,164 topics and 162,121 semantic relationships. The main root is Computer Science; however, the ontology includes also a few secondary roots, such as Linguistics, Geometry, Semantics, and so on.
CSO presents two main advantages over manually crafted categorisations used in Computer Science (e.g., 2012 ACM Classification, Microsoft Academic Search Classification). First, it can characterise higher-level research areas by means of hundreds of sub-topics and related terms, which enables to map very specific terms to higher-level research areas. Secondly, it can be easily updated by running Klink-2 on a set of new publications.

Invited Talk – Early detection of Research Topics
On 2nd of August 2018, I have been invited by Boris Veytsman, Principal Research Scientist at Chan Zuckerberg Initiative (formerly Meta), to give a talk about my PhD work. Differently from my previous talk to the ORNL group, I had the opportunity to describe my doctoral work more comprehensively. More specifically, I initially showed what is available […]

Invited Talk – AUGUR: Forecasting the Emergence of New Research Topics
On 30th Jul 2018, I have been invited from Dasha Herrmannova, former PhD student at the KMi, to give a talk at the “Machine Learning and Graph Mining for Big Scholarly Data” workshop organised for the Computational Data Analytics Group at Oak Ridge National Laboratory (ORNL). In this talk, named “AUGUR: Forecasting the Emergence of New […]
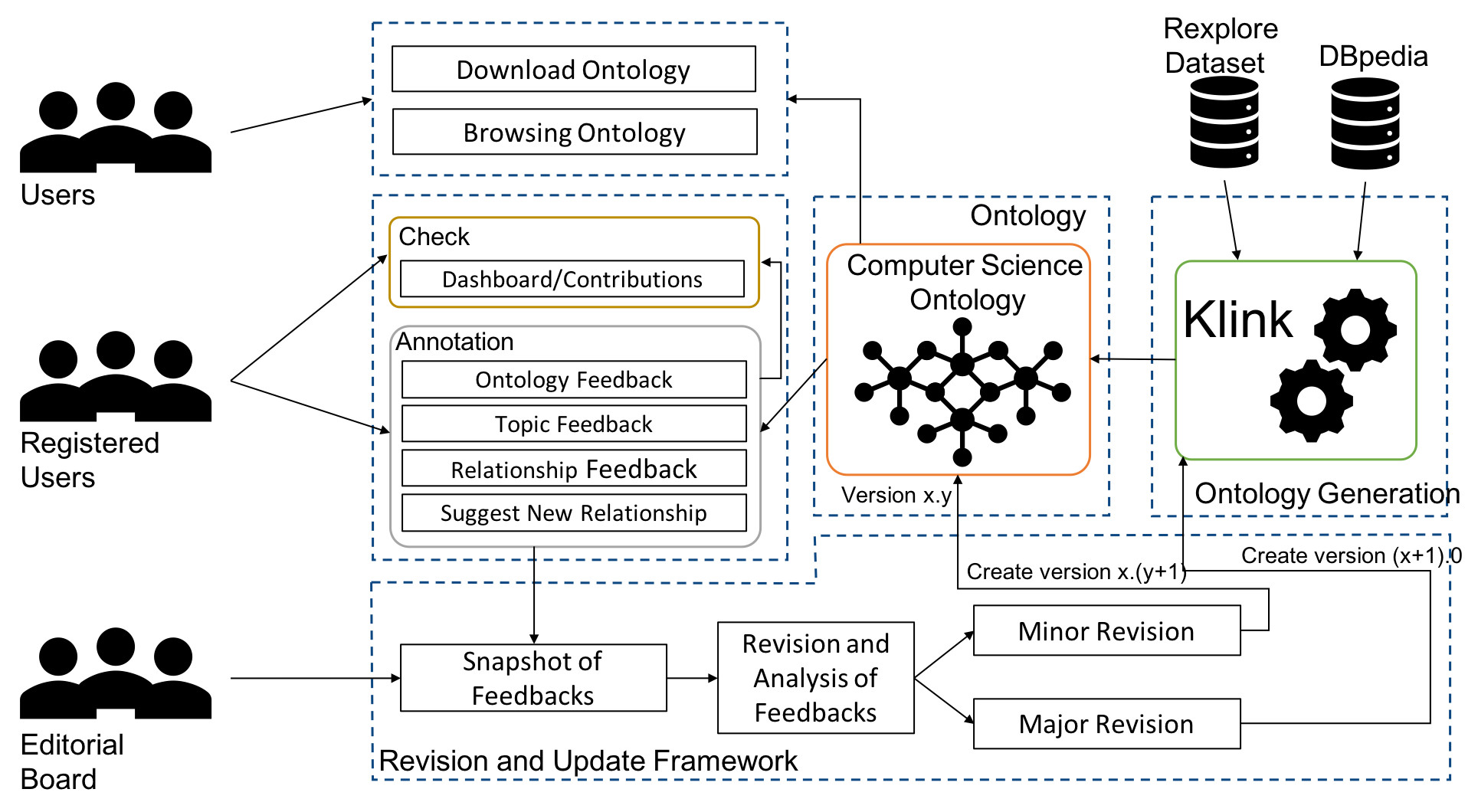
The Computer Science Ontology: A Large-Scale Taxonomy of Research Areas
Ontologies of research areas are important tools for characterising, exploring, and analysing the research landscape. Some fields of research are comprehensively described by large-scale taxonomies, e.g., MeSH in Biology and PhySH in Physics. Conversely, current Computer Science taxonomies are coarse-grained and tend to evolve slowly. For instance, the ACM classification scheme contains only about 2K research topics and the last version dates back to 2012. In this paper, we introduce the Computer Science Ontology (CSO), a large-scale, automatically generated ontology of research areas, which includes about 26K topics and 226K semantic relationships. It was created by applying the Klink-2 algorithm on a very large dataset of 16M scientific articles.