“Link Prediction of Weighted Triples for Knowledge Graph Completion Within the Scholarly Domain” is a journal paper accepted at IEEE Access
Mojtaba Nayyeri1,2, Gökce Müge Cil1, Sahar Vahdati2, Francesco Osborne3, Andrey Kravchenko4, Simone Angioni5, Angelo Salatino3, Diego Reforgiato Recupero5, Enrico Motta3, Jens Lehmann1,6
1 SDA Research Group, University of Bonn, 53115 Bonn, Germany
2 Nature-Inspired Machine Intelligence, Institute for Applied Informatics (InfAI), 01069 Dresden, Germany
3 Knowledge Media Institute, The Open University, Milton Keynes MK7 6AA, U.K.
4 Christ Church, University of Oxford, Oxford OX1 1DP, U.K.
5 Department of Mathematics and Computer Science, University of Cagliari, 09124 Cagliari, Italy
6 Fraunhofer IAIS, 53757 Dresden, Germany
Abstract
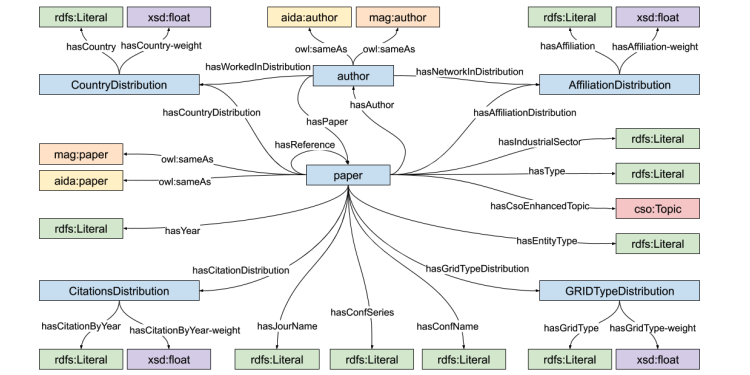
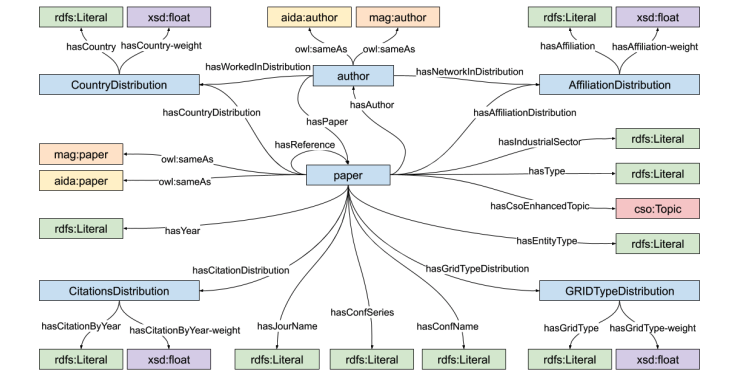
Knowledge graphs (KGs) are widely used for modeling scholarly communication, performing scientometric analyses, and supporting a variety of intelligent services to explore the literature and predict research dynamics. However, they often suffer from incompleteness (e.g., missing affiliations, references, research topics), leading to a reduced scope and quality of the resulting analyses. This issue is usually tackled by computing knowledge graph embeddings (KGEs) and applying link prediction techniques. However, only a few KGE models are capable of taking weights of facts in the knowledge graph into account. Such weights can have different meanings, e.g. describe the degree of association or the degree of truth of a certain triple. In this paper, we propose the Weighted Triple Loss, a new loss function for KGE models that takes full advantage of the additional numerical weights on facts and it is even tolerant to incorrect weights. We also extend the Rule Loss, a loss function that is able to exploit a set of logical rules, in order to work with weighted triples. The evaluation of our solutions on several knowledge graphs indicates significant performance improvements with respect to the state of the art. Our main use case is the large-scale AIDA knowledge graph, which describes 21 million research articles. Our approach enables to complete information about affiliation types, countries, and research topics, greatly improving the scope of the resulting scientometrics analyses and providing better support to systems for monitoring and predicting research dynamics.
Download
Download from DOI (open access): https://doi.org/10.1109/ACCESS.2021.3105183