
“Leveraging Knowledge Graph Technologies to Assess Journals and Conferences at Springer Nature” is an In-Use paper presented at the 21st International Semantic Web Conference (ISWC 2022). Simone Angioni1, Angelo Antonio Salatino2, Francesco Osborne2,3,AliaksandrBirukou4, Diego Reforgiato Recupero1, Enrico Motta2 1 Department of Mathematics and Computer Science, University of Cagliari (Italy) 2 Knowledge Media Institute, The Open […]
Tag: science of science

Sci-K 2022 – International Workshop on Scientific Knowledge: Representation, Discovery, and Assessment
“Sci-K 2022 – International Workshop on Scientific Knowledge: Representation, Discovery, and Assessment” is the introductory chapter of the workshop proceedings of “Sci-K 2022 – International Workshop on Scientific Knowledge: Representation, Discovery, and Assessment” co-located with The Web Conference 2022. Paolo Manghi1, Andrea Mannocci1, Francesco Osborne2, Dimitris Sacharidis3, Angelo Salatino2, Thanasis Vergoulis4 1 CNR-ISTI – National […]

The AIDA Dashboard: a Web Application for Assessing and Comparing Scientific Conferences
“The AIDA Dashboard: a Web Application for Assessing and Comparing Scientific Conferences” is a research paper submitted to IEEE Access. Simone Angioni1, Angelo Antonio Salatino2, Francesco Osborne2, Diego Reforgiato Recupero1, Enrico Motta2 1 Department of Mathematics and Computer Science, University of Cagliari (Italy) 2 Knowledge Media Institute, The Open University, Milton Keynes (UK) Abstract […]

Characterising Research Areas in the field of AI
“Characterising Research Areas in the field of AI” is a research paper submitted to the special track “Statistical Methods for Science Mapping” on “51st Scientific Meeting of the Italian Statistical Society”. Alessandra Belfiore1, Angelo Salatino2, Francesco Osborne2 1 Università della Campania Luigi Vanvitelli, Caserta (Italy) 2 Knowledge Media Institute, The Open University, Milton Keynes (UK) Abstract […]
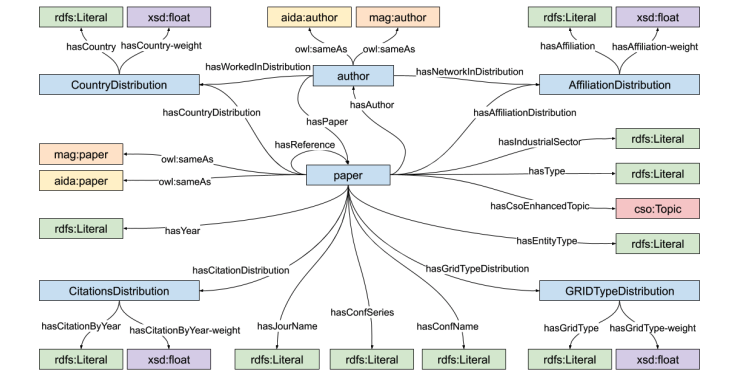
Link Prediction of Weighted Triples for Knowledge Graph Completion Within the Scholarly Domain
“Link Prediction of Weighted Triples for Knowledge Graph Completion Within the Scholarly Domain” is a journal paper accepted at IEEE Access Mojtaba Nayyeri1,2, Gökce Müge Cil1, Sahar Vahdati2, Francesco Osborne3, Andrey Kravchenko4, Simone Angioni5, Angelo Salatino3, Diego Reforgiato Recupero5, Enrico Motta3, Jens Lehmann1,6 1 SDA Research Group, University of Bonn, 53115 Bonn, Germany 2 […]

CSO Classifier 3.0: A Scalable Unsupervised Method for Classifying Documents in Terms of Research Topics
“CSO Classifier 3.0: A Scalable Unsupervised Method for Classifying Documents in Terms of Research Topics” is a journal paper accepted at the Special Issue of “TPDL 2019 & 2020” at Scientometrics. Angelo Salatino, Francesco Osborne, Enrico Motta Abstract Classifying scientific articles, patents, and other documents according to the relevant research topics is an important task, […]

Scientific Knowledge Graphs: an Overview
On 12th May 2021, I have been invited by Dimitris Sacharidis to give a lecture to the master course is INFO-H509 “XML and Web Technologies” at the Université Libre de Bruxelles. Abstract In the last decade, several Scientific Knowledge Graphs (SKG) were released, representing scientific knowledge in a structured, interlinked, and semantically rich manner. But, what […]

Applying Machine Learning Techniques to Big Data in the Scholarly Domain
Ontologies of research areas have been proven to be useful in many application for analysing and making sense of scholarly data. In this lecture, I will present how we produced the Computer Science Ontology (CSO), which is the largest ontology of research areas in the field of Computer Science, and discuss a number of applications that build on CSO, to support high-level tasks, such as topic classification, research trends forecasting, metadata extraction, and recommendation of books.

ResearchFlow: Understanding the Knowledge Flow between Academia and Industry
“ResearchFlow: Understanding the Knowledge Flow between Academia and Industry” is a conference paper submitted to Knowledge Engineering and Knowledge Management – 22nd International Conference, EKAW 2020. Angelo Salatino, Francesco Osborne, Enrico Motta Abstract Understanding, monitoring, and predicting the flow of knowledge between academia and industry is of critical importance for a variety of stakeholders, including governments, funding […]
1st Workshop on Scientific Knowledge Graphs (SKG2020)
In the last decade, we experienced an urgent need for a flexible, context-sensitive, fine-grained, and machine-actionable representation of scholarly knowledge and corresponding infrastructures for knowledge curation, publishing and processing. Such technical infrastructures are becoming increasingly popular in representing scholarly knowledge as structured, interlinked, and semantically rich Scholarly Knowledge Graphs (SKG).
The 1st Workshop on Scientific Knowledge Graphs (SKG2020) aims at bringing together researchers and practitioners from different fields (including, but not limited to, Digital Libraries, Information Extraction, Machine Learning, Semantic Web, Knowledge Engineering, Natural Language Processing, Scholarly Communication, and Bibliometrics) in order to explore innovative solutions and ideas for the production and consumption of Scientific Knowledge Graphs (SKGs).