
On March 22, 2024, the AI for the Research Ecosystem workshop (#AI4RE) took place in London, kindly hosted by UCL in the wonderful surroundings of Chandler House. The workshop was part of the Turing Institue’s AI UK Fringe series of events which took place around the U.K. The workshop focused on the intersection of the […]
Category: Artificial Intelligence

Enriching Data Lakes with Knowledge Graphs
“Enriching Data Lakes with Knowledge Graphs” is a workshop paper published at “Knowledge Graph Generation from Text” co-located with ESWC 2022. Alessandro Chessa1,2, Gianni Fenu3, Enrico Motta4, Francesco Osborne4,5, Diego Reforgiato Recupero3,Angelo Antonio Salatino4, Luca Secchi1 1 Linkalab s.r.l., Cagliari, Italy 2 Luiss Data Lab, Rome, Italy 3 University of Cagliari, Cagliari, Italy 4 Knowledge Media Institute, The […]

The AIDA Dashboard: a Web Application for Assessing and Comparing Scientific Conferences
“The AIDA Dashboard: a Web Application for Assessing and Comparing Scientific Conferences” is a research paper submitted to IEEE Access. Simone Angioni1, Angelo Antonio Salatino2, Francesco Osborne2, Diego Reforgiato Recupero1, Enrico Motta2 1 Department of Mathematics and Computer Science, University of Cagliari (Italy) 2 Knowledge Media Institute, The Open University, Milton Keynes (UK) Abstract […]

Characterising Research Areas in the field of AI
“Characterising Research Areas in the field of AI” is a research paper submitted to the special track “Statistical Methods for Science Mapping” on “51st Scientific Meeting of the Italian Statistical Society”. Alessandra Belfiore1, Angelo Salatino2, Francesco Osborne2 1 Università della Campania Luigi Vanvitelli, Caserta (Italy) 2 Knowledge Media Institute, The Open University, Milton Keynes (UK) Abstract […]

AIDA: a Knowledge Graph about Research Dynamics in Academia and Industry
“AIDA: a Knowledge Graph about Research Dynamics in Academia and Industry” is a research paper published at the Special Issue on “Scientific Knowledge Graphs and Research Impact Assessment” at Quantitative Science Studies (QSS by MIT Press). Simone Angioni1, Angelo Antonio Salatino2, Francesco Osborne2, Diego Reforgiato Recupero1, Enrico Motta2 1 Department of Mathematics and Computer Science, University […]
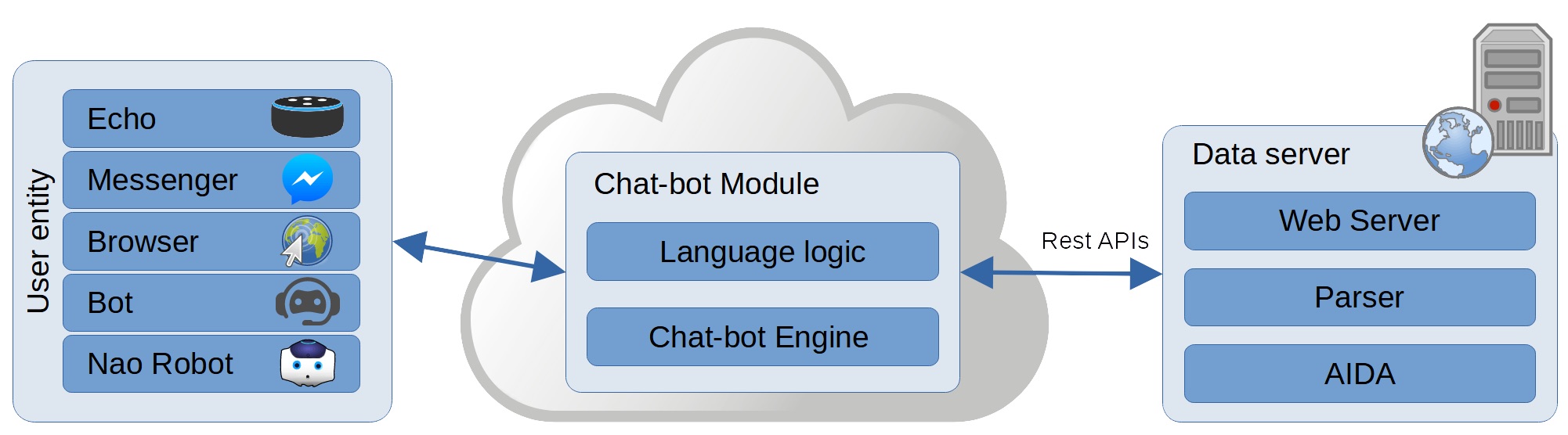
AIDA-Bot: A Conversational Agent to Explore Scholarly Knowledge Graphs
“AIDA-Bot: A Conversational Agent to ExploreScholarly Knowledge Graphs” is a demo paper accepted for presentation at the International Semantic Web Conference (ISWC 2021) poster and demo session. Antonello Meloni1, Simone Angioni1, Angelo Antonio Salatino2, Francesco Osborne2, Diego Reforgiato Recupero1, Enrico Motta2 1 Department of Mathematics and Computer Science, University of Cagliari (Italy) 2 Knowledge Media […]
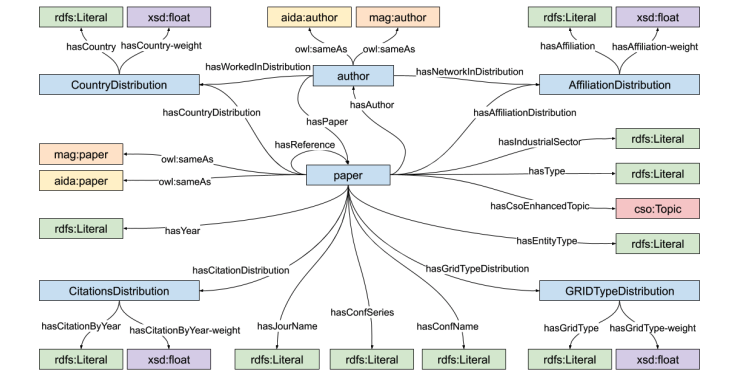
Link Prediction of Weighted Triples for Knowledge Graph Completion Within the Scholarly Domain
“Link Prediction of Weighted Triples for Knowledge Graph Completion Within the Scholarly Domain” is a journal paper accepted at IEEE Access Mojtaba Nayyeri1,2, Gökce Müge Cil1, Sahar Vahdati2, Francesco Osborne3, Andrey Kravchenko4, Simone Angioni5, Angelo Salatino3, Diego Reforgiato Recupero5, Enrico Motta3, Jens Lehmann1,6 1 SDA Research Group, University of Bonn, 53115 Bonn, Germany 2 […]

CSO Classifier 3.0
Abstract Classifying research papers according to their research topics is an important task to improve their retrievability, assist the creation of smart analytics, and support a variety of approaches for analysing and making sense of the research environment. In this repository, we present the CSO Classifier, a new unsupervised approach for automatically classifying research papers […]

Trans4E: Link Prediction on Scholarly Knowledge Graphs
“Trans4E: Link Prediction on Scholarly Knowledge Graphs” is a journal paper submitted to the Special Issue on “Knowledge Graph Representation & Reasoning” at the Neurocomputing Journal Mojtaba Nayyeria, Gokce Muge Cila, Sahar Vahdatib, Francesco Osborned, Mahfuzur Rahmana,Simone Angionie, Angelo Salatinod, Diego Reforgiato Recuperoe, Nadezhda Vassilyevaa, Enrico Mottad and Jens Lehmanna,c aSDA Research Group, University […]
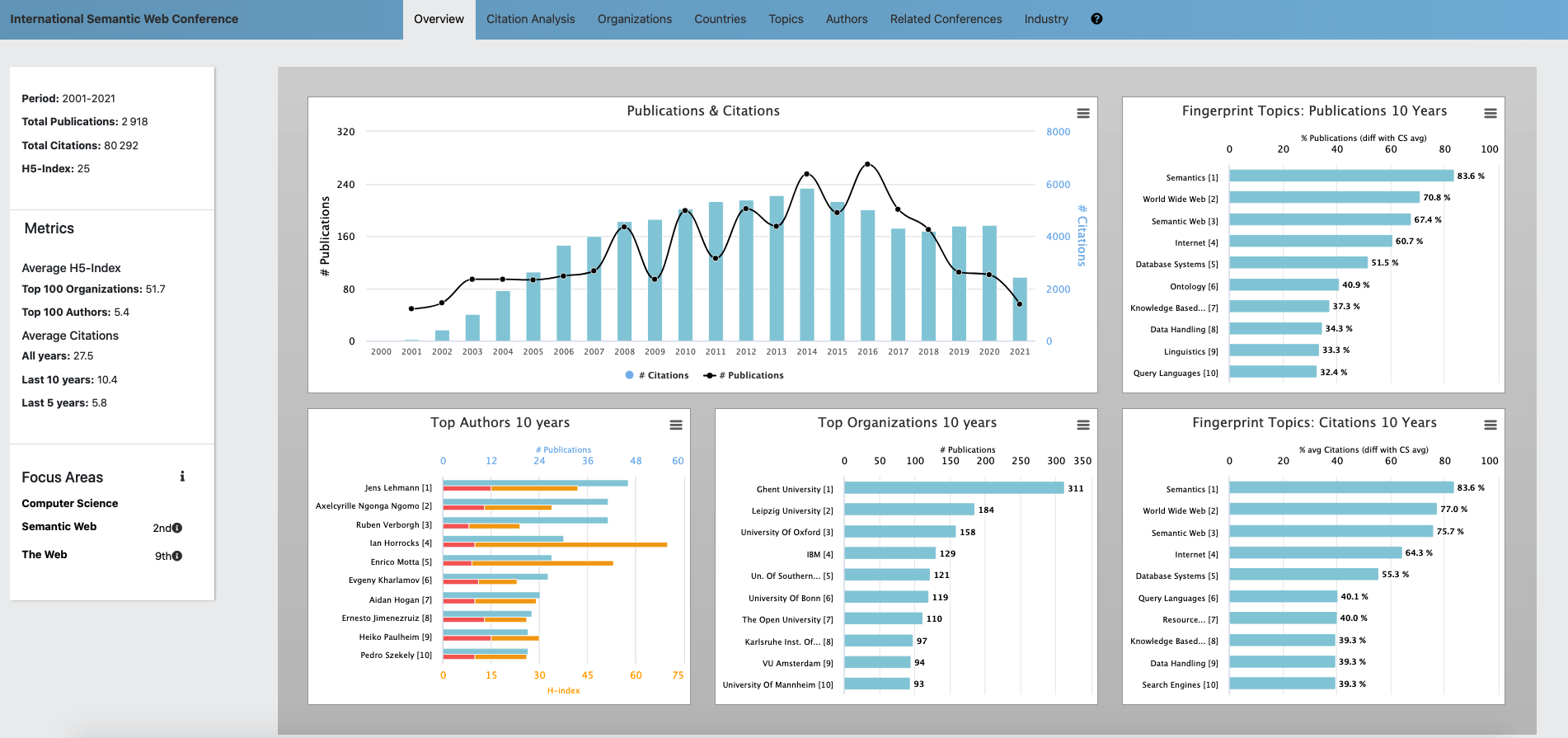
AIDA Dashboard
The AIDA Dashboard is a web application that allows users to visualize several kind of analytics about a specific conference (see Figure 1). The backend is developed in Python, while the frontend is in HTML5 and Javascript. The AIDA Dashboard builds on the Academia/Industry DynAmics knowledge graph (AIDA), a large knowledge base describing 14M articles […]