
The CSO Classifier is an application for automatically classifying academic papers according to the rich taxonomy of topics from CSO. The aim is to facilitate the adoption of CSO across the various communities engaged with scholarly data and to foster the development of new applications based on this knowledge base.
Category: Publications2018
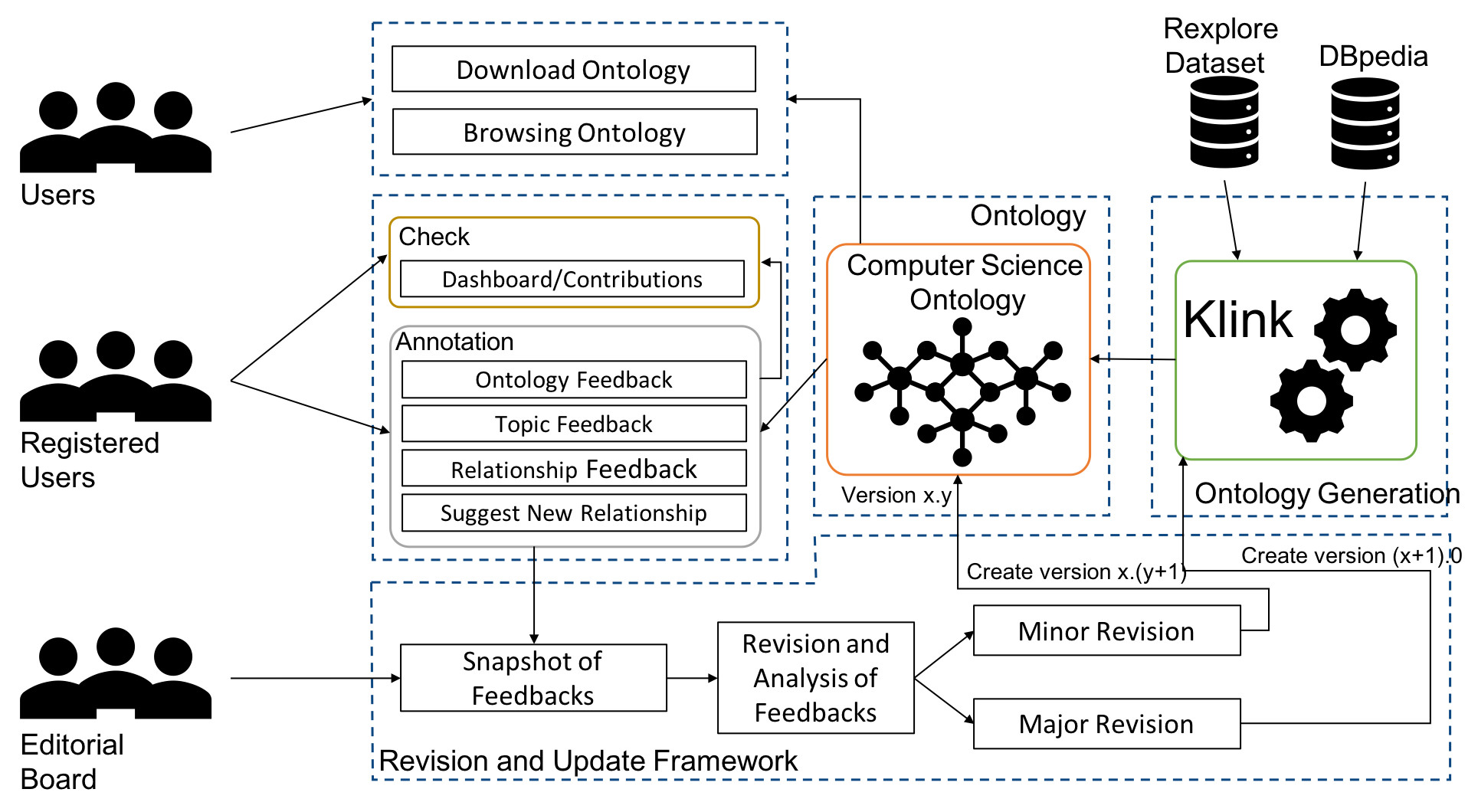
The Computer Science Ontology: A Large-Scale Taxonomy of Research Areas
Ontologies of research areas are important tools for characterising, exploring, and analysing the research landscape. Some fields of research are comprehensively described by large-scale taxonomies, e.g., MeSH in Biology and PhySH in Physics. Conversely, current Computer Science taxonomies are coarse-grained and tend to evolve slowly. For instance, the ACM classification scheme contains only about 2K research topics and the last version dates back to 2012. In this paper, we introduce the Computer Science Ontology (CSO), a large-scale, automatically generated ontology of research areas, which includes about 26K topics and 226K semantic relationships. It was created by applying the Klink-2 algorithm on a very large dataset of 16M scientific articles.
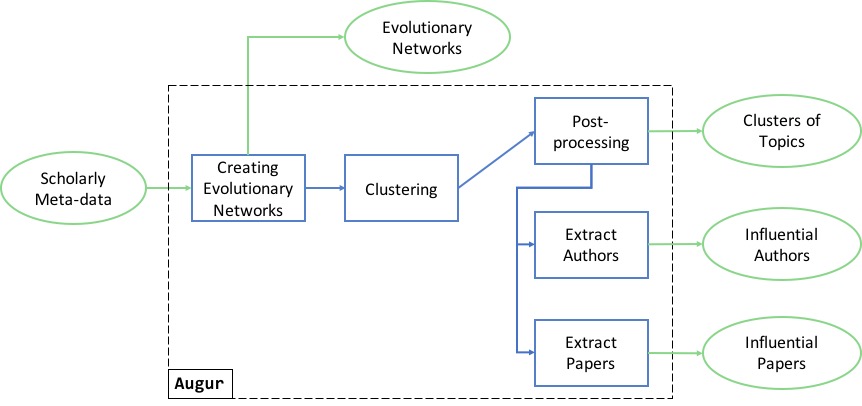
AUGUR: Forecasting the Emergence of New Research Topics
“AUGUR: Forecasting the Emergence of New Research Topics” is a paper submitted to the ACM/IEEE Joint Conference on Digital Libraries 2018, presented on June 5 2018, in Fort Worth, TX, USA Angelo Salatino, Francesco Osborne and Enrico Motta Abstract Being able to rapidly recognise new research trends is strategic for many stakeholders, including universities, […]