
“R-Classify: Extracting Research Papers’ Relevant Concepts from a Controlled Vocabulary” is a software paper accepted at Software Impacts. Tanay Aggarwal, Angelo Antonio Salatino, Francesco Osborne, Enrico Motta Knowledge Media Institute, The Open University, Milton Keynes (UK) Abstract In the past few decades, we saw a proliferation of scientific articles available online. This data-rich environment offers several opportunities […]
Category: Web Technologies

Leveraging Knowledge Graph Technologies to Assess Journals and Conferences at Springer Nature
“Leveraging Knowledge Graph Technologies to Assess Journals and Conferences at Springer Nature” is an In-Use paper presented at the 21st International Semantic Web Conference (ISWC 2022). Simone Angioni1, Angelo Antonio Salatino2, Francesco Osborne2,3,AliaksandrBirukou4, Diego Reforgiato Recupero1, Enrico Motta2 1 Department of Mathematics and Computer Science, University of Cagliari (Italy) 2 Knowledge Media Institute, The Open […]

The AIDA Dashboard: a Web Application for Assessing and Comparing Scientific Conferences
“The AIDA Dashboard: a Web Application for Assessing and Comparing Scientific Conferences” is a research paper submitted to IEEE Access. Simone Angioni1, Angelo Antonio Salatino2, Francesco Osborne2, Diego Reforgiato Recupero1, Enrico Motta2 1 Department of Mathematics and Computer Science, University of Cagliari (Italy) 2 Knowledge Media Institute, The Open University, Milton Keynes (UK) Abstract […]

Scientific Knowledge Graphs: an Overview
On 12th May 2021, I have been invited by Dimitris Sacharidis to give a lecture to the master course is INFO-H509 “XML and Web Technologies” at the Université Libre de Bruxelles. Abstract In the last decade, several Scientific Knowledge Graphs (SKG) were released, representing scientific knowledge in a structured, interlinked, and semantically rich manner. But, what […]

The AIDA Dashboard: Analysing Conferences with Semantic Technologies
“The AIDA Dashboard: Analysing Conferences with Semantic Technologies” is a demo paper submitted to the Posters and Demos tracks of the 19th International Semantic Web Conference. Simone Angioni1, Francesco Osborne2, Angelo A. Salatino2, Diego Reforgiato Recupero1, Enrico Motta2 1 University of Cagliari, Via Università 40, 09124 Cagliari 2 Knowledge Media Institute, The Open University, […]
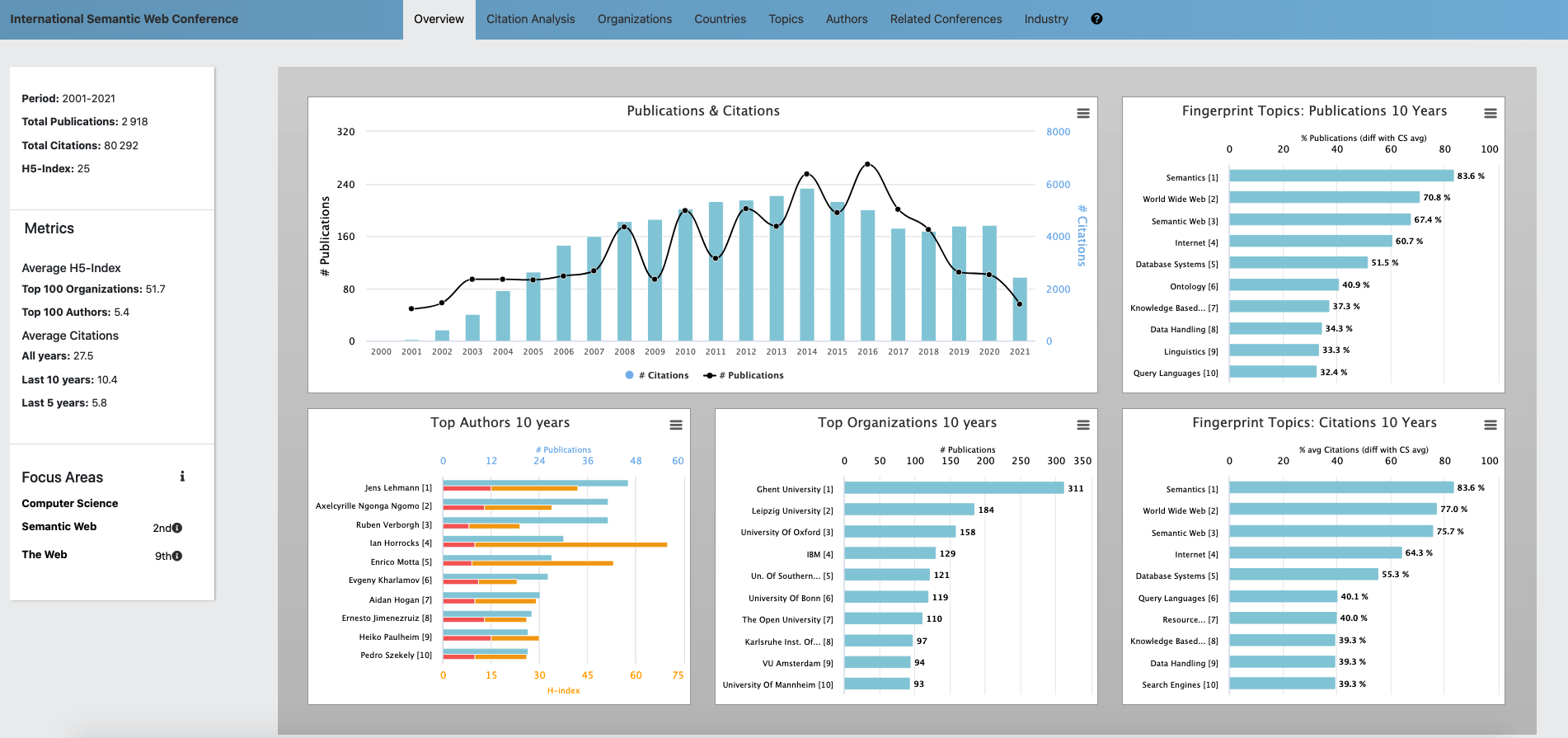
AIDA Dashboard
The AIDA Dashboard is a web application that allows users to visualize several kind of analytics about a specific conference (see Figure 1). The backend is developed in Python, while the frontend is in HTML5 and Javascript. The AIDA Dashboard builds on the Academia/Industry DynAmics knowledge graph (AIDA), a large knowledge base describing 14M articles […]

I launched an online course on Instagram, here is my lesson learned
THIS IS A DRAFT – WORK IN PROGRESS During the COVID-19 outbreak many people relied more and more on web technologies like such as video calls and social networks, to fulfil their social needs. I decided to design and release an online course on Instagram so that users while consuming content could be engaged in […]
1st Workshop on Scientific Knowledge Graphs (SKG2020)
In the last decade, we experienced an urgent need for a flexible, context-sensitive, fine-grained, and machine-actionable representation of scholarly knowledge and corresponding infrastructures for knowledge curation, publishing and processing. Such technical infrastructures are becoming increasingly popular in representing scholarly knowledge as structured, interlinked, and semantically rich Scholarly Knowledge Graphs (SKG).
The 1st Workshop on Scientific Knowledge Graphs (SKG2020) aims at bringing together researchers and practitioners from different fields (including, but not limited to, Digital Libraries, Information Extraction, Machine Learning, Semantic Web, Knowledge Engineering, Natural Language Processing, Scholarly Communication, and Bibliometrics) in order to explore innovative solutions and ideas for the production and consumption of Scientific Knowledge Graphs (SKGs).

The Computer Science Ontology: A Comprehensive Automatically-Generated Taxonomy of Research Areas
Ontologies of research areas are important tools for characterising, exploring, and analysing the research landscape. Some fields of research are comprehensively described by large-scale taxonomies, e.g., MeSH in Biology and PhySH in Physics. Conversely, current Computer Science taxonomies are coarse-grained and tend to evolve slowly. For instance, the ACM classification scheme contains only about 2K research topics and the last version dates back to 2012. In this paper, we introduce the Computer Science Ontology (CSO), a large-scale, automatically generated ontology of research areas, which includes about 14K topics and 162K semantic relationships. It was created by applying the Klink-2 algorithm on a very large dataset of 16M scientific articles. CSO presents two main advantages over the alternatives: i) it includes a very large number of topics that do not appear in other classifications, and ii) it can be updated automatically by running Klink-2 on recent corpora of publications. CSO powers several tools adopted by the editorial team at Springer Nature and has been used to enable a variety of solutions, such as classifying research publications, detecting research communities, and predicting research trends. To facilitate the uptake of CSO, we have also released the CSO Classifier, a tool for automatically classifying research papers, and the CSO Portal, a web application that enables users to download, explore, and provide granular feedback on CSO. Users can use the portal to navigate and visualise sections of the ontology, rate topics and relationships, and suggest missing ones. The portal will support the publication of and access to regular new releases of CSO, with the aim of providing a comprehensive resource to the various research communities engaged with scholarly data.
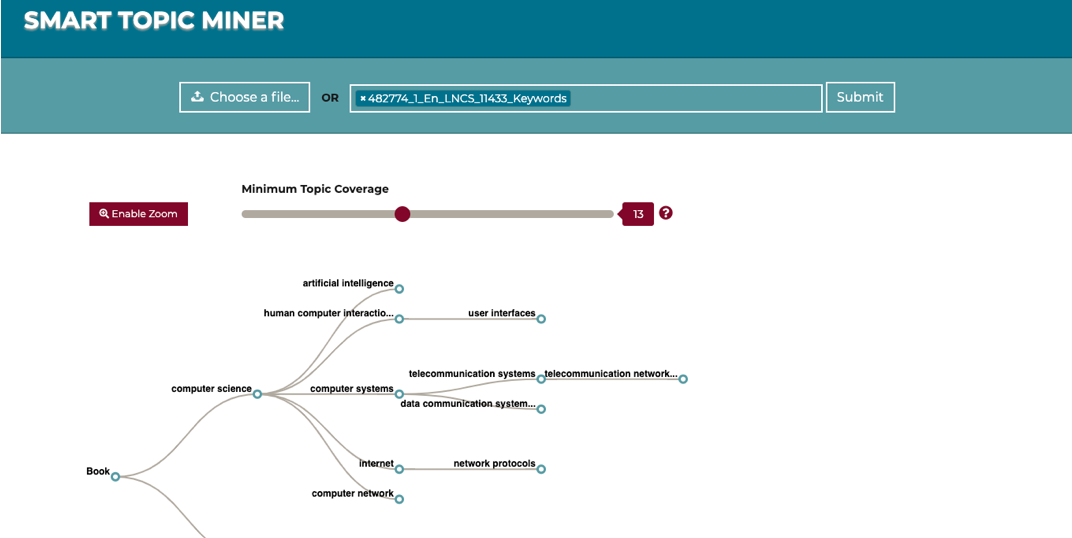
Smart Topics Miner 2: Improving Proceedings Retrievability at Springer Nature
Producing a robust and comprehensive representation of the research topics covered by a scientific publication is a crucial task that has a major impact on its retrievability and consequently on the diffusion of the relevant scientific ideas. Springer Nature, the world’s largest academic book publisher, has typically entrusted this task to the most expert editors, which had to manually analyse new books and produce a list of the most relevant topics. To support Springer Nature in this task, we developed Smart Topic Miner, an application that assists the editorial team in annotating proceedings books according to a large-scale ontology of research areas. Over the past three years, we evolved this application according to the editors’ feedback and developed a new engine, a new interface, and several other functionalities. In this demo paper, we present Smart Topic Miner 2, the most recent version of the tool, which is being regularly utilized by editors in Germany, China, Brazil, and Japan to annotate all book series covering conference proceedings in Computer Science, for a total of about 800 volumes per year.