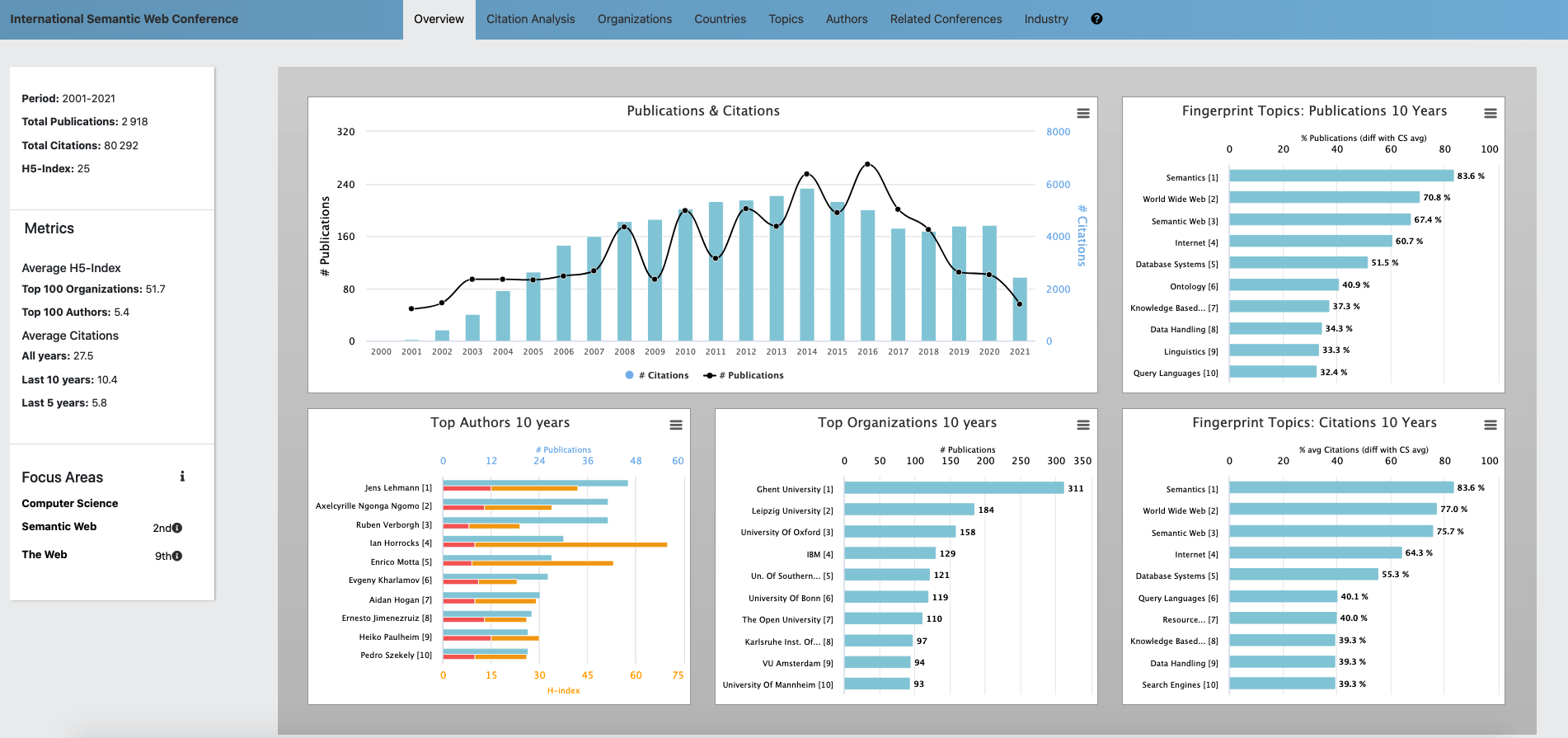
The AIDA Dashboard is a web application that allows users to visualize several kind of analytics about a specific conference (see Figure 1). The backend is developed in Python, while the frontend is in HTML5 and Javascript. The AIDA Dashboard builds on the Academia/Industry DynAmics knowledge graph (AIDA), a large knowledge base describing 14M articles […]
Category: Projects

Academia/Industry DynAmics (AIDA) Knowledge Graph
Academia and industry share a complex, multifaceted, and symbiotic relationship. Analysing the knowledge flow between them, understanding which directions have the biggest potential, and discovering the best strategies to harmonise their efforts is a critical task for several stakeholders. While research publications and patents are an ideal media to analyse this space, current datasets of […]
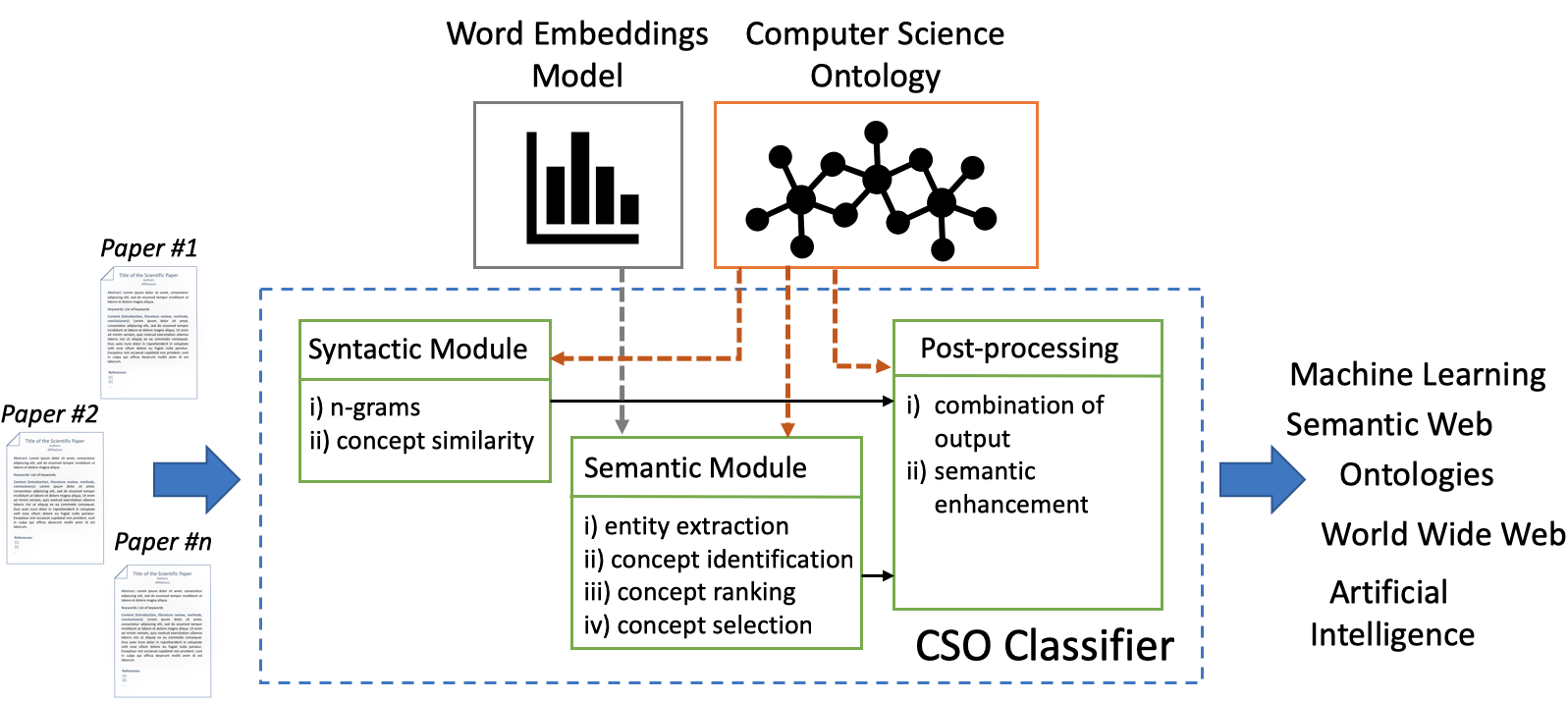
New release: CSO Classifier v2.1
We are pleased to announce that we recently created a new release of the CSO Classifier (v2.1), an application for automatically classifying research papers according to the Computer Science Ontology (CSO). Recently, we have been intensively working on improving its scalability, removing all its bottlenecks and making sure it could be run on large corpus. […]

CSO Classifier
Classifying research papers according to their research topics is an important task to improve their retrievability, assist the creation of smart analytics, and support a variety of approaches for analysing and making sense of the research environment. In this page, we present the CSO Classifier, a new unsupervised approach for automatically classifying research papers according to the Computer Science Ontology (CSO), a comprehensive ontology of research areas in the field of Computer Science.
Computer Science Ontology
The Computer Science Ontology is a large-scale ontology of research areas that was automatically generated using the Klink-2 algorithm on a dataset of about 16 million publications, mainly in the field of Computer Science. In the rest of the paper, we will refer to this corpus as the Rexplore dataset.
The current version of CSO includes 14,164 topics and 162,121 semantic relationships. The main root is Computer Science; however, the ontology includes also a few secondary roots, such as Linguistics, Geometry, Semantics, and so on.
CSO presents two main advantages over manually crafted categorisations used in Computer Science (e.g., 2012 ACM Classification, Microsoft Academic Search Classification). First, it can characterise higher-level research areas by means of hundreds of sub-topics and related terms, which enables to map very specific terms to higher-level research areas. Secondly, it can be easily updated by running Klink-2 on a set of new publications.

Supporting Editorial Activities at Springer Nature
The project aims at fostering Springer Nature editorial activities by supporting them with a variety of smart solutions leveraging artificial intelligence, data mining, and semantic technologies. In particular, the KMi team will support Springer Nature editorial team in classifying proceedings and other editorial products, taking informed decisions about their marketing strategy, and improve their internal classification.
CityLABS Project
CityLabs is a collaborative project that is grant funded by ERDF. The Open University, ZTE and Fronesys have pooled their skills to create an environment that engages SMEs in research and business development. CityLabs is a place for SMEs to work with academic and industry leaders to develop concepts into prototypes for new products and […]
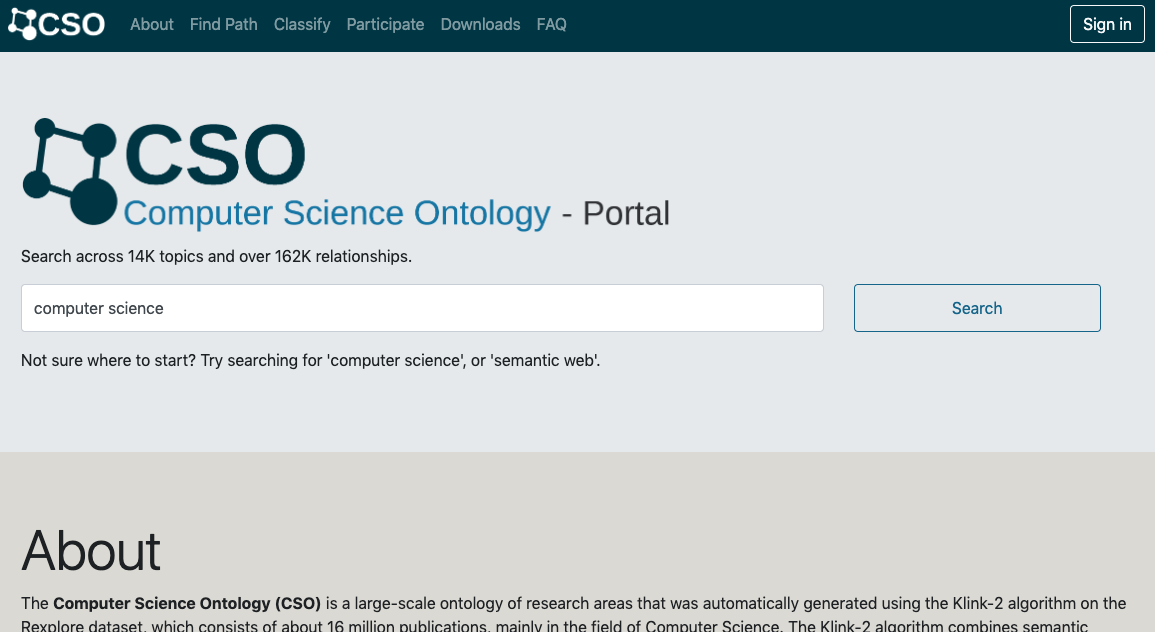
Computer Science Ontology Portal (or simply CSO Portal)
The Computer Science Ontology Portal (also referred to simply as CSO Portal) is a web application that enables users to download, explore, and provide granular feedback on CSO at different levels. This last feature allows us to periodically review the status ontology and release new version according to the received feedbacks.
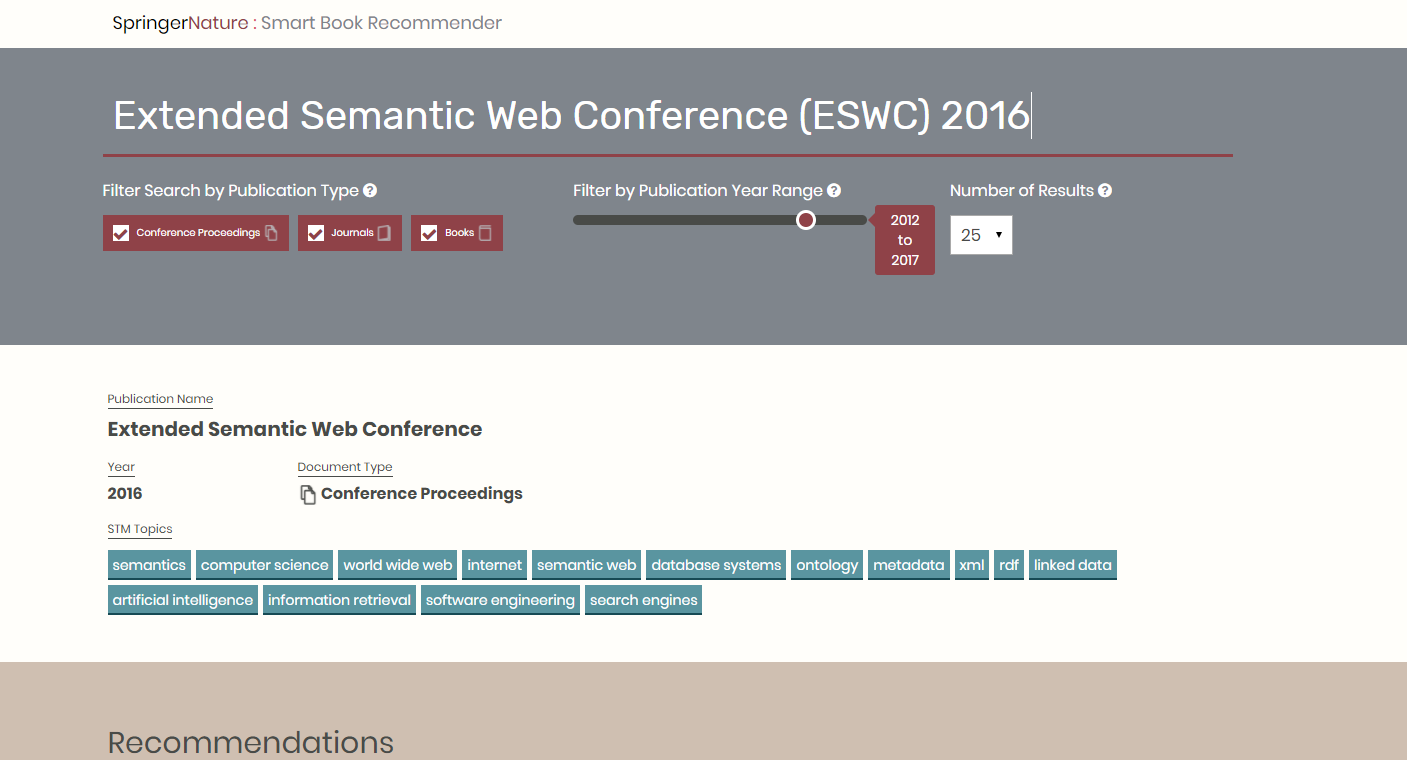
Smart Book Recommender
The Smart Book Recommender (SBR) is a semantic application designed to support the Springer Nature editorial team in promoting their publications at Computer Science venues. It takes as input the proceedings of a conference and suggests books, journals, and other conference proceedings that are likely to be relevant to the attendees of the conference in question. It […]

MK:SMART – Garden Monitor
I joined the project in March 2016 until September 2016, as Project Officer. My activities in this project involved setting up a network of sensors linked to MK Smart Data Hub. These sensors monitor the soil moisture of our users in a trial period, so that we could perform the evaluation of the following technology: Unnecessary […]