
“The AIDA Dashboard: a Web Application for Assessing and Comparing Scientific Conferences” is a research paper submitted to IEEE Access. Simone Angioni1, Angelo Antonio Salatino2, Francesco Osborne2, Diego Reforgiato Recupero1, Enrico Motta2 1 Department of Mathematics and Computer Science, University of Cagliari (Italy) 2 Knowledge Media Institute, The Open University, Milton Keynes (UK) Abstract […]
Tag: Scholarly Ontologies

AIDA: a Knowledge Graph about Research Dynamics in Academia and Industry
“AIDA: a Knowledge Graph about Research Dynamics in Academia and Industry” is a research paper published at the Special Issue on “Scientific Knowledge Graphs and Research Impact Assessment” at Quantitative Science Studies (QSS by MIT Press). Simone Angioni1, Angelo Antonio Salatino2, Francesco Osborne2, Diego Reforgiato Recupero1, Enrico Motta2 1 Department of Mathematics and Computer Science, University […]

Assessing Scientific Conferences through Knowledge Graphs
“Assessing Scientific Conferences through Knowledge Graphs” is a paper published at the Industry Track of the 2021 International Semantic Web Conference. Simone Angioni1, Angelo Antonio Salatino2, Francesco Osborne2, Aliaksandr Birukou3, Diego Reforgiato Recupero1, Enrico Motta2 1 Department of Mathematics and Computer Science, University of Cagliari (Italy) 2 Knowledge Media Institute, The Open University, Milton Keynes (UK) […]

Applying Machine Learning Techniques to Big Data in the Scholarly Domain
Ontologies of research areas have been proven to be useful in many application for analysing and making sense of scholarly data. In this lecture, I will present how we produced the Computer Science Ontology (CSO), which is the largest ontology of research areas in the field of Computer Science, and discuss a number of applications that build on CSO, to support high-level tasks, such as topic classification, research trends forecasting, metadata extraction, and recommendation of books.

The AIDA Dashboard: Analysing Conferences with Semantic Technologies
“The AIDA Dashboard: Analysing Conferences with Semantic Technologies” is a demo paper submitted to the Posters and Demos tracks of the 19th International Semantic Web Conference. Simone Angioni1, Francesco Osborne2, Angelo A. Salatino2, Diego Reforgiato Recupero1, Enrico Motta2 1 University of Cagliari, Via Università 40, 09124 Cagliari 2 Knowledge Media Institute, The Open University, […]
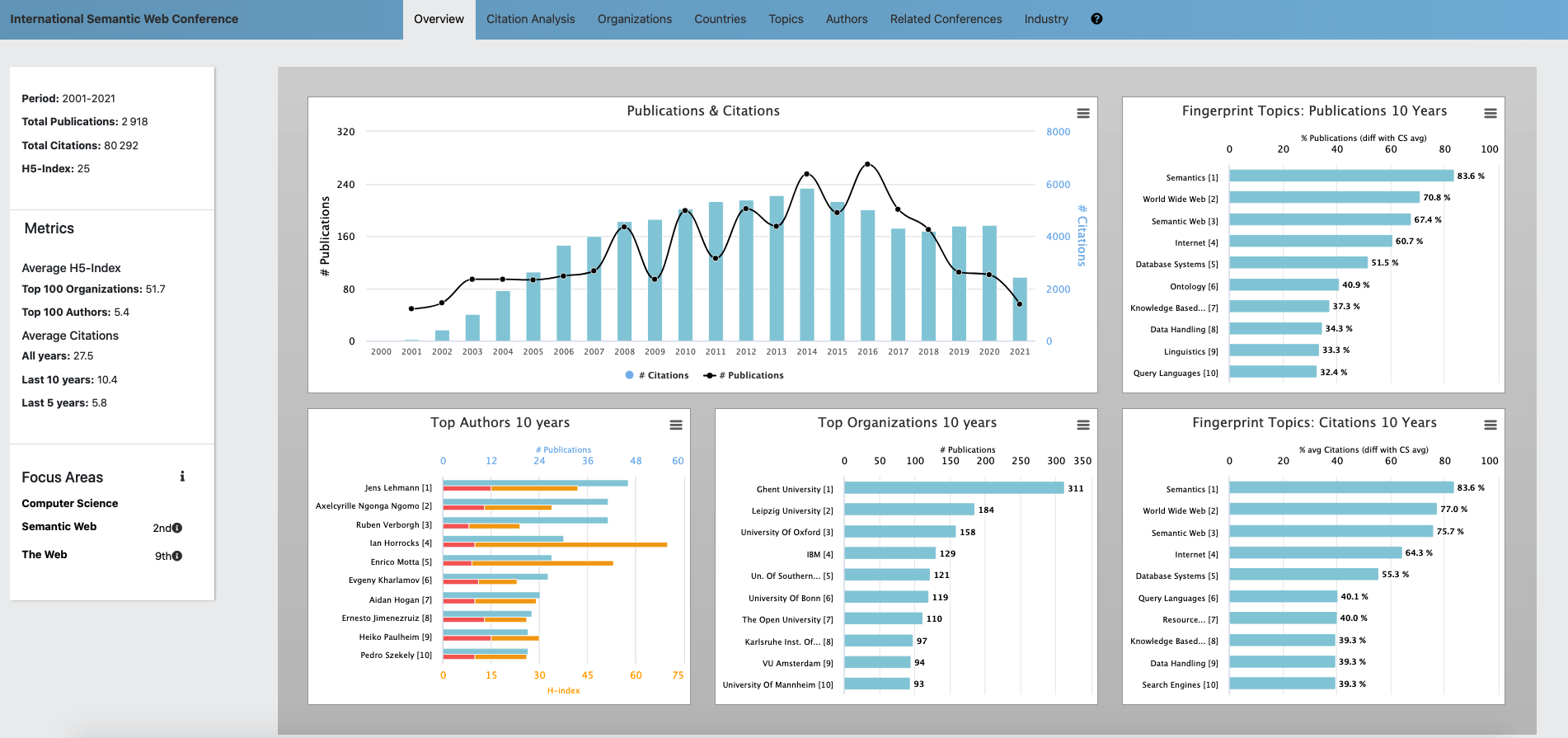
AIDA Dashboard
The AIDA Dashboard is a web application that allows users to visualize several kind of analytics about a specific conference (see Figure 1). The backend is developed in Python, while the frontend is in HTML5 and Javascript. The AIDA Dashboard builds on the Academia/Industry DynAmics knowledge graph (AIDA), a large knowledge base describing 14M articles […]

Integrating Knowledge Graphs for Analysing Academia and Industry Dynamics
Academia and industry are constantly engaged in a joint effort for producing scientific knowledge that will shape the society of the future. Analysing the knowledge flow between them and understanding how they influence each other is a critical task for researchers, governments, funding bodies, investors, and companies. However, current corpora are unfit to support large-scale analysis of the knowledge flow between academia and industry since they lack of a good characterization of research topics and industrial sectors. In this short paper, we introduce the Academia/Industry DynAmics (AIDA) Knowledge Graph, which characterizes 14M papers and 8M patents according to the research topics drawn from the Computer Science Ontology. 4M papers and 5M patents are also classified according to the type of the author’s affiliations (academy, industry, or collaborative) and 66 industrial sectors (e.g., automotive, financial, energy, electronics) obtained from DBpedia. AIDA was generated by an automatic pipeline that integrates several knowledge graphs and bibliographic corpora, including Microsoft Academic Graph, Dimensions, English DBpedia, the Computer Science Ontology, and the Global Research Identifier Database.

Academia/Industry DynAmics (AIDA) Knowledge Graph
Academia and industry share a complex, multifaceted, and symbiotic relationship. Analysing the knowledge flow between them, understanding which directions have the biggest potential, and discovering the best strategies to harmonise their efforts is a critical task for several stakeholders. While research publications and patents are an ideal media to analyse this space, current datasets of […]
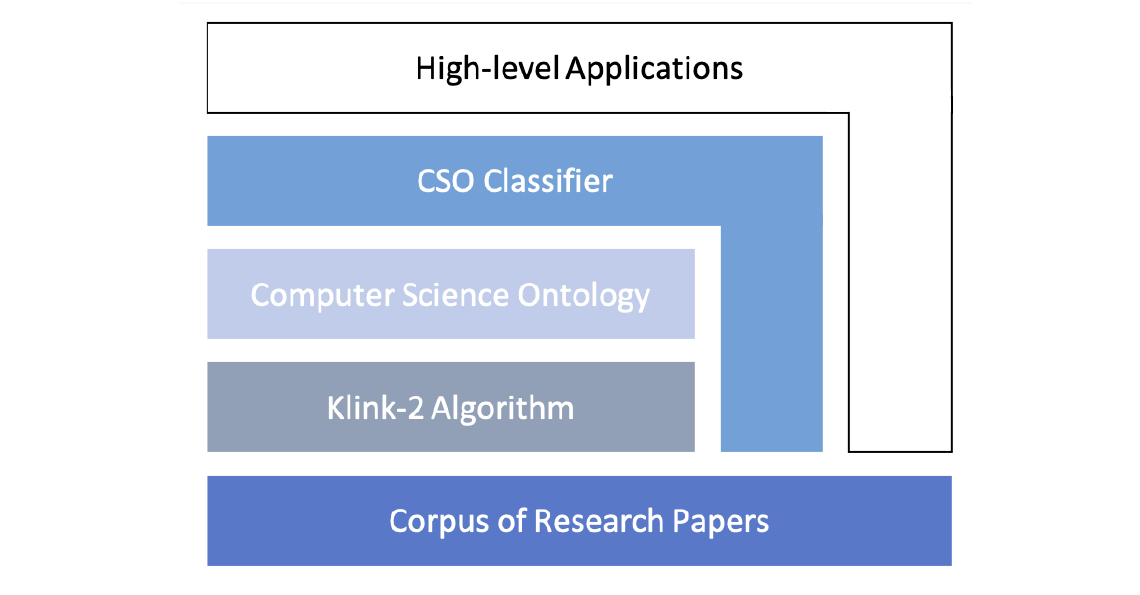
Ontology Extraction and Usage in the Scholarly Knowledge Domain
Ontologies of research areas have been proven to be useful in many application for analysing and making sense of scholarly data. In this chapter, we present the Computer Science Ontology (CSO), which is the largest ontology of research areas in the field of Computer Science, and discuss a number of applications that build on CSO, to support high-level tasks, such as topic classification, metadata extraction, and recommendation of books.

The Computer Science Ontology: A Comprehensive Automatically-Generated Taxonomy of Research Areas
Ontologies of research areas are important tools for characterising, exploring, and analysing the research landscape. Some fields of research are comprehensively described by large-scale taxonomies, e.g., MeSH in Biology and PhySH in Physics. Conversely, current Computer Science taxonomies are coarse-grained and tend to evolve slowly. For instance, the ACM classification scheme contains only about 2K research topics and the last version dates back to 2012. In this paper, we introduce the Computer Science Ontology (CSO), a large-scale, automatically generated ontology of research areas, which includes about 14K topics and 162K semantic relationships. It was created by applying the Klink-2 algorithm on a very large dataset of 16M scientific articles. CSO presents two main advantages over the alternatives: i) it includes a very large number of topics that do not appear in other classifications, and ii) it can be updated automatically by running Klink-2 on recent corpora of publications. CSO powers several tools adopted by the editorial team at Springer Nature and has been used to enable a variety of solutions, such as classifying research publications, detecting research communities, and predicting research trends. To facilitate the uptake of CSO, we have also released the CSO Classifier, a tool for automatically classifying research papers, and the CSO Portal, a web application that enables users to download, explore, and provide granular feedback on CSO. Users can use the portal to navigate and visualise sections of the ontology, rate topics and relationships, and suggest missing ones. The portal will support the publication of and access to regular new releases of CSO, with the aim of providing a comprehensive resource to the various research communities engaged with scholarly data.