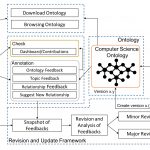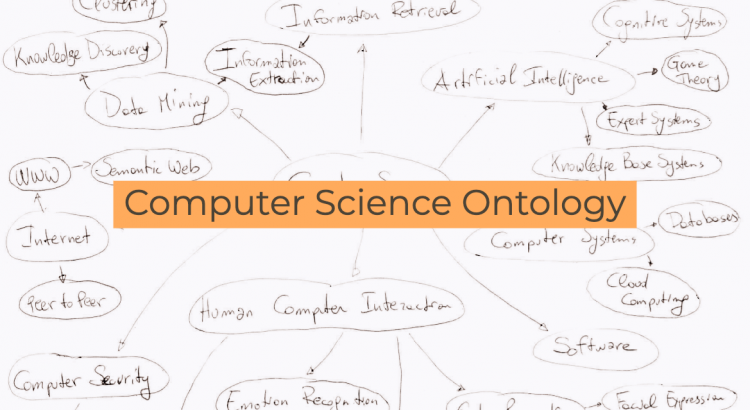
The Computer Science Ontology is a large-scale ontology of research areas that was automatically generated using the Klink-2 algorithm [1] on a dataset of about 16 million publications, mainly in the field of Computer Science. In the rest of the paper, we will refer to this corpus as the Rexplore dataset [2].
The current version of CSO includes 14,164 topics and 162,121 semantic relationships. The main root is Computer Science; however, the ontology includes also a few secondary roots, such as Linguistics, Geometry, Semantics, and so on.
CSO presents two main advantages over manually crafted categorisations used in Computer Science (e.g., 2012 ACM Classification, Microsoft Academic Search Classification). First, it can characterise higher-level research areas by means of hundreds of sub-topics and related terms, which enables to map very specific terms to higher-level research areas. Secondly, it can be easily updated by running Klink-2 on a set of new publications.
You can browse the CSO using the CSO Portal.
Data Model
The CSO data model [3] is an extension of SKOS [4] and it includes eight semantic relations:
- relatedEquivalent, which is a subproperty of skos:related, indicates that two topics can be treated as equivalent for the purpose of exploring research data (e.g., Ontology Matching and Ontology Mapping). For the sake of avoiding technical jargon, in the CSO Portal this predicate is referred to as alternative label of.
- superTopicOf, which is a subproperty of skos:narrower, indicates that a topic is a super-area of another one (e.g., Semantic Web is a super-area of Linked Data). This predicate is referred to as parent of in the portal. The inverse of this relationship is subTopicOf.
- contributesTo, which indicates that the research output of one topic contributes to another. For instance, research in Ontology Engineering contributes to Semantic Web, but arguably Ontology Engineering is not a sub-area of Semantic Web – that is, there is plenty of research in Ontology Engineering outside the Semantic Web area.
- owl:sameAs, which is used for mapping CSO topics to equivaled entities in other knowledge graphs (DBpedia, Freebase, Wikidata, YAGO, and Cyc).
- schema:relatedLink, which links CSO concepts to relevant web pages that either describe the research topics (Wikipedia articles) or provide additional information about the research domains (Microsoft Academic).
- preferentialEquivalent, which is used to state the main label for topics belonging to a cluster of relatedEquivalent. For instance, the topics Ontology Matching and Ontology Alignment both have their preferentialEquivalent set to Ontology Matching. Similarly to relatedEquivalent, in our data model we defined preferentialEquivalent as a subproperty of skos:related.
- rdf:type, this relation is used to state that a resource is an instance of a class. For example, a resource in our ontology is an instance of Topic, which is a subclass of skos:Concept.
- rdfs:label, this relation is used to provide a human-readable version of a resource’s name.
More information including how we generated CSO, are available on [5].
Resource Exploration
Each resource is available at its own URI. For instance, the resource ‘semantic web‘ is browsable at the URI https://cso.kmi.open.ac.uk/topics/semantic_web.
The CSO Portal allows to negotiate the content to serve different representations of the same resource (URI), with the following formats:
- HTML. The resource is explorable via browser (i.e., by clicking here).
- RDF/XML. Specifying the Accept header application/rdf+xml, or adding rdf or xml as extension to the resource, e.g., semantic web.rdf
- Turtle. Specifying the Accept header text/turtle, or adding ttl as extension to the resource, e.g., semantic web.ttl
- JSON-LD. Specifying the Accept header application/json or application/ld+json, or adding json or jsonld as extension to the resource, e.g., semantic web.json
- N-Triples. Specifying the Accept header application/n-triples, or adding nt as extension to the resource, e.g., semantic web.nt
Details:
| Format | Header | Resource |
|---|---|---|
| HTML | – | semantic web |
| RDF/XML | application/rdf+xml | semantic web.rdf or semantic web.xml |
| Turtle | text/turtle | semantic web.ttl |
| JSON-LD | application/json or application/ld+json | semantic web.json or semantic web.jsonld |
| N-Triples | application/n-triples | semantic web.nt |
Download
The Computer Science Ontology is available for download in various formats (N-Triples, OWL, and CSV) from https://cso.kmi.open.ac.uk/downloads. This ontology is licensed under a Creative Commons Attribution 4.0 International License (CC BY 4.0) [6] meaning that everyone is allowed to:
- copy and redistribute the material in any medium or format;
- remix, transform, and build upon the material for any purpose, even commercially.
Footnotes
[1] Osborne, F., Motta, E.: Klink-2: Integrating Multiple Web Sources to Generate Semantic Topic Networks. In: The Semantic Web – ISWC 2015. pp. 408–424 (2015).
[2] Osborne, F., Motta, E., Mulholland, P.: Exploring scholarly data with rexplore. Semant. Web — ISWC 2013. 8218 LNCS, 460–477 (2013)
[3] CSO Schema – http://cso.kmi.open.ac.uk/schema/cso.
[4] SKOS Simple Knowledge Organization System – http://www.w3.org/2004/02/skos.
[5] Salatino, A. A., Thanapalasingam, T., Mannocci, A., Osborne, F., & Motta, E. (2018, October). The computer science ontology: a large-scale taxonomy of research areas. In International Semantic Web Conference (pp. 187-205). Springer, Cham.
[6] CC BY 4.0 International License – https://creativecommons.org/licenses/by/4.0.