
“CSO Classifier 3.0: A Scalable Unsupervised Method for Classifying Documents in Terms of Research Topics” is a journal paper accepted at the Special Issue of “TPDL 2019 & 2020” at Scientometrics. Angelo Salatino, Francesco Osborne, Enrico Motta Abstract Classifying scientific articles, patents, and other documents according to the relevant research topics is an important task, […]
Tag: Ontology

How to use the CSO Classifier in other domains
Being able to characterise research papers according to their topics enables a multitude of high-level applications such as i) categorise proceedings in digital libraries, ii) semantically enhance the metadata of scientific publications, iii) generate recommendations, iv) produce smart analytics, v) detect research trends, and others.
In our recent work, we designed and developed an unsupervised approach to automatically classify research papers according to an ontology of research areas in the field of Computer Science. This approach uses well-known technologies from the field of Natural Language Processing which makes it easily generalisable. In this article, we will show how we can customise the CSO Classifier and apply it to other fields of Science.
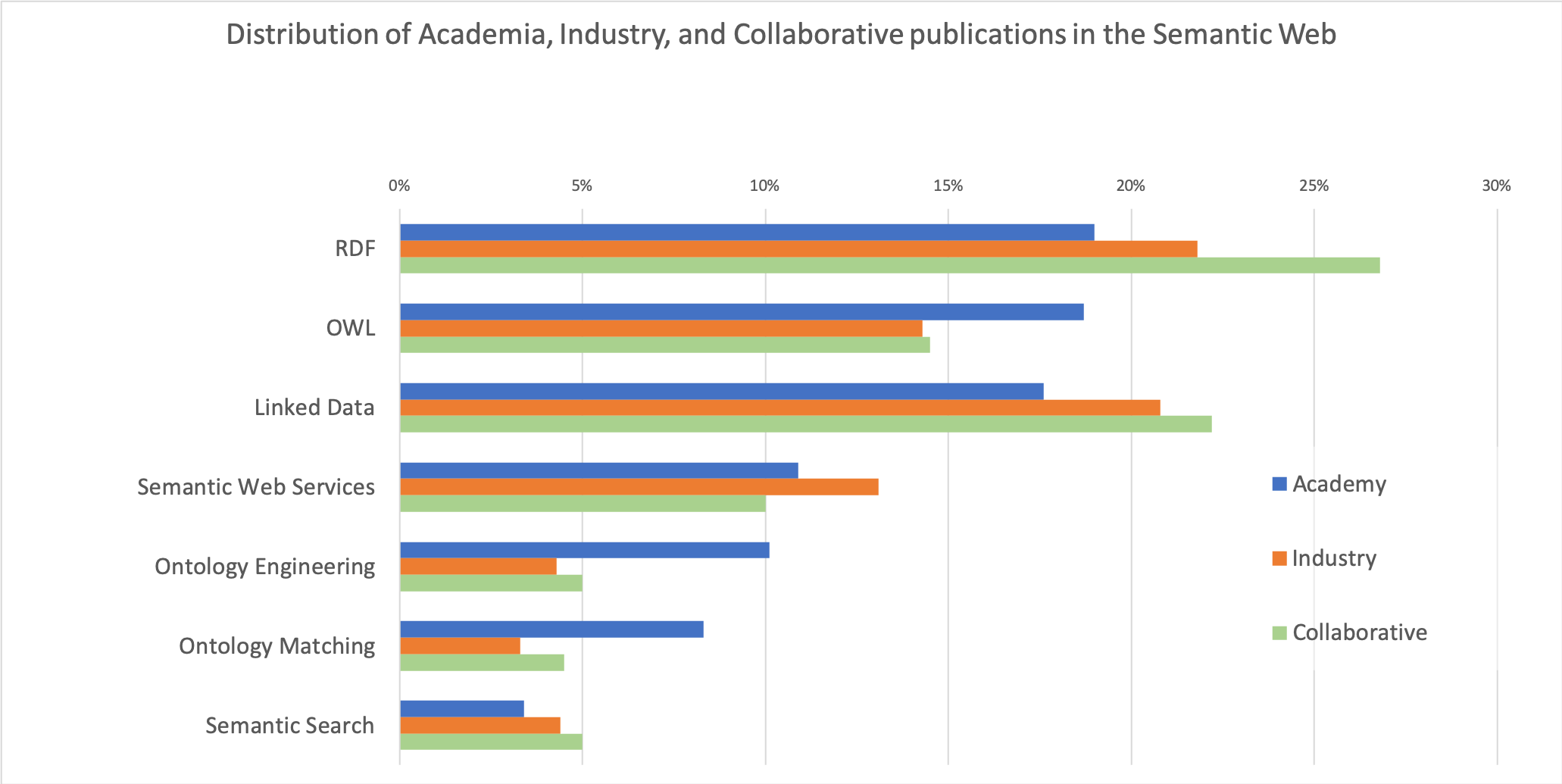
Integrating Knowledge Graphs for Comparing the Scientific Output of Academia and Industry
Analysing the relationship between academia and industry allows us to understand how the knowledge produced by the universities is being adopted and enriched by the industrial sector, and ultimately affects society through the release of relevant products and services. In this paper, we present a preliminary approach to assess and compare the research outputs of academia and industry. This solution integrates data from several knowledge graphs describing scientific articles (Microsoft Academics Graph), research topics (Computer Science Ontology), organizations (Global Research Identifier Database), and types of industry (DBpedia). We focus on the Semantic Web as exemplary field and report several insights regarding the different behaviours of academia and industry, and the types of industries most active in this field.

The CSO Classifier: Ontology-Driven Detection of Research Topics in Scholarly Articles
Classifying research papers according to their research topics is an important task to improve their retrievability, assist the creation of smart analytics, and support a variety of approaches for analysing and making sense of the research environment. In this paper, we present the CSO Classifier, a new unsupervised approach for automatically classifying research papers according to the Computer Science Ontology (CSO), a comprehensive ontology of research areas in the field of Computer Science. The CSO Classifier takes as input the metadata associated with a research paper (title, abstract, keywords) and returns a selection of research concepts drawn from the ontology. The approach was evaluated on a gold standard of manually annotated articles yielding a significant improvement over alternative methods.
The Open University and Springer Nature launch the Computer Science Ontology
Springer Nature and the Knowledge Media Institute (KMi) of The Open University are partnering to provide a comprehensive Computer Science Ontology (CSO) to a broad range of communities engaged with scholarly data. CSO can be accessed free of charge through the CSO Portal, a web application that enables users to download, explore, and provide feedback on the ontology.
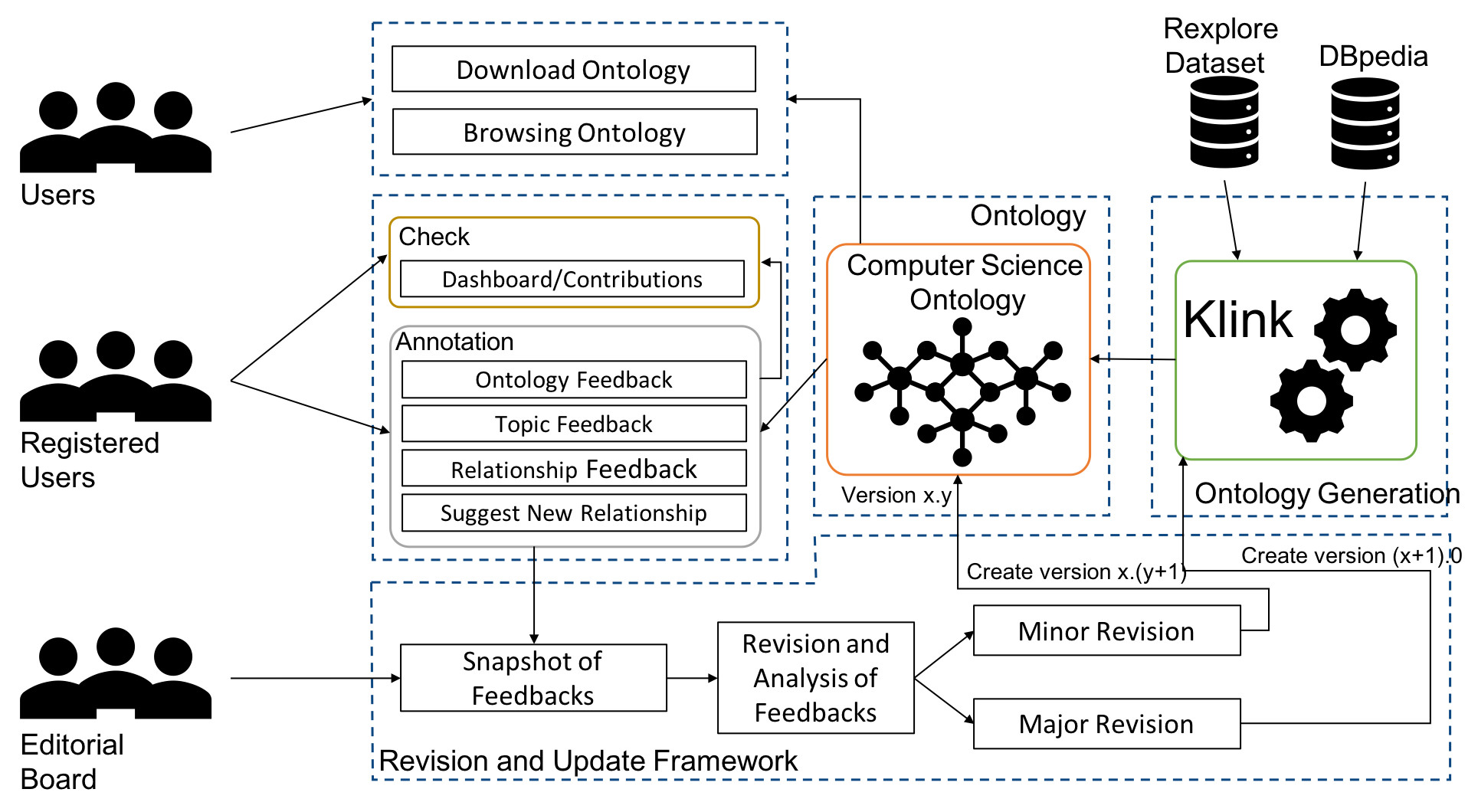
The Computer Science Ontology: A Large-Scale Taxonomy of Research Areas
Ontologies of research areas are important tools for characterising, exploring, and analysing the research landscape. Some fields of research are comprehensively described by large-scale taxonomies, e.g., MeSH in Biology and PhySH in Physics. Conversely, current Computer Science taxonomies are coarse-grained and tend to evolve slowly. For instance, the ACM classification scheme contains only about 2K research topics and the last version dates back to 2012. In this paper, we introduce the Computer Science Ontology (CSO), a large-scale, automatically generated ontology of research areas, which includes about 26K topics and 226K semantic relationships. It was created by applying the Klink-2 algorithm on a very large dataset of 16M scientific articles.
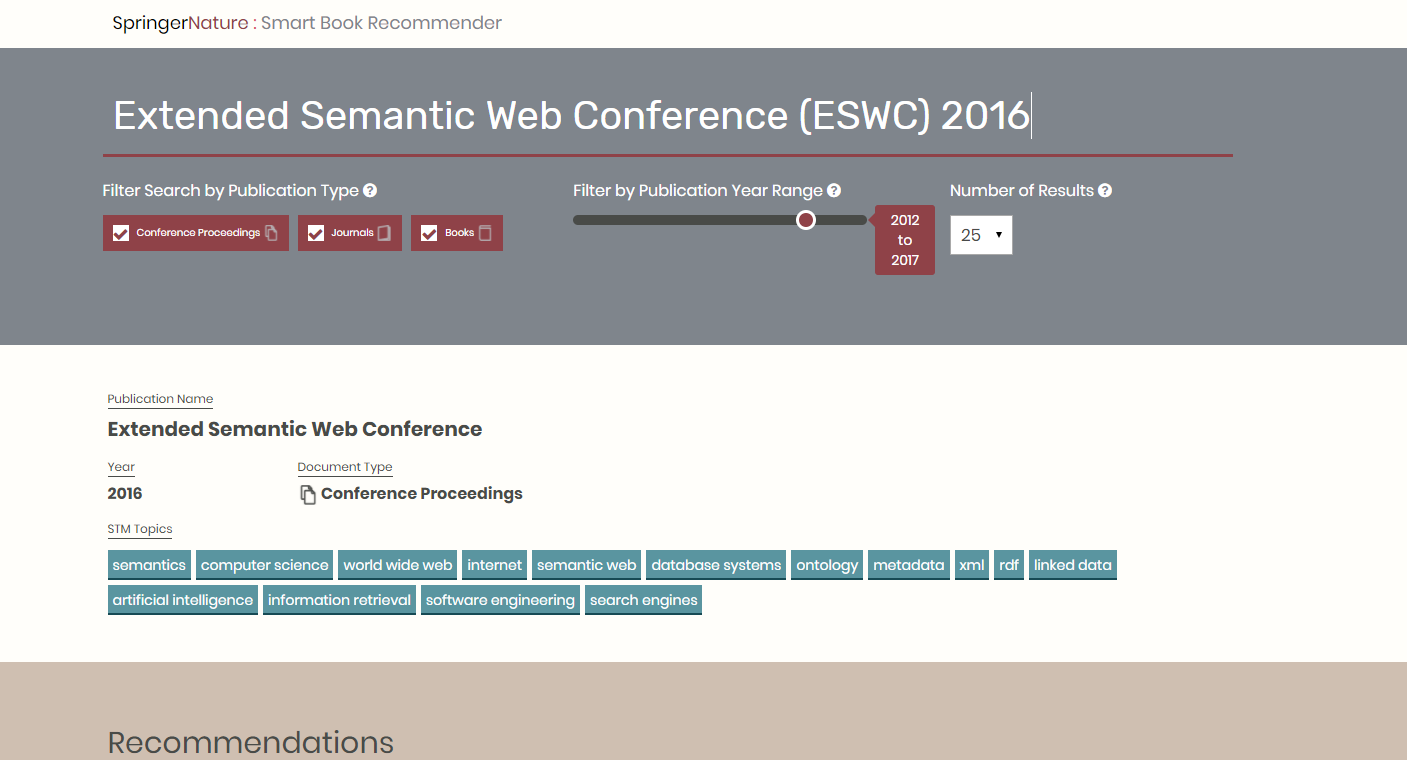
Smart Book Recommender
The Smart Book Recommender (SBR) is a semantic application designed to support the Springer Nature editorial team in promoting their publications at Computer Science venues. It takes as input the proceedings of a conference and suggests books, journals, and other conference proceedings that are likely to be relevant to the attendees of the conference in question. It […]
Smart Book Recommender: A Semantic Recommendation Engine for Editorial Products
“Smart Book Recommender: A Semantic Recommendation Engine for Editorial Products” is a poster paper that will be presented at the International Semantic Web Conference (ISWC) 2017, 21-25 October 2017, Vienna, Austria. Authors Francesco Osborne, Thiviyan Thanapalasingam, Angelo Salatino, Aliaksandr Birukou and Enrico Motta Abstract Academic publishers, such as Springer Nature, need to constantly make informed decisions […]

Advances Towards Early Detection of Research Topics
Acknowledging new trends in the research environment is important for many stakeholders, such as researchers, institutional funding bodies, academic publishers, and companies. In particular, being able to identify them as soon as possible can bring an important strategical advantage. A trend is usually defined as the general direction in which something is evolving. It is […]

Detection of Embryonic Research Topics by Analysing Semantic Topic Networks
“Detection of Embryonic Research Topics by Analysing Semantic Topic Networks” is a workshop paper I presented at the SAVESD workshop held in conjunction with the World Wide Web Conference in 2016 in Montreal (CA). Angelo Antonio Salatino and Enrico Motta Abstract Being aware of new research topics is an important asset for anybody involved in […]