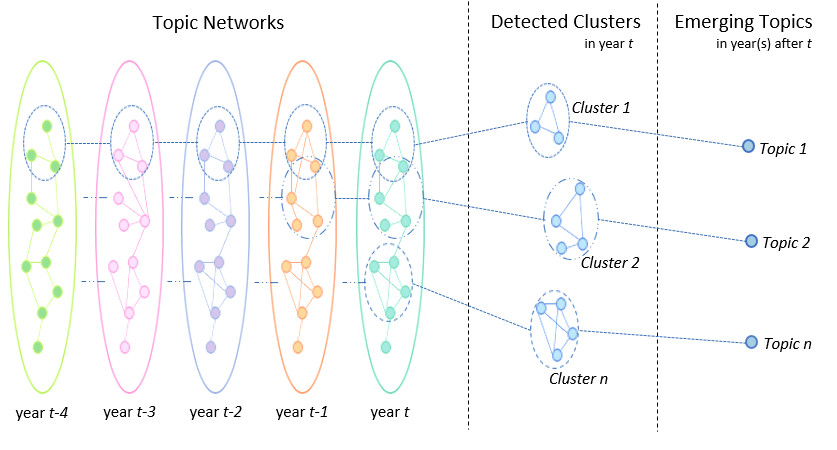
Being able to rapidly recognise new research trends is strategic for many stakeholders, including universities, institutional funding bodies, academic publishers and companies. The literature presents several approaches to identifying the emergence of new research topics, which rely on the assumption that the topic is already exhibiting a certain degree of popularity and consistently referred to by a community of researchers. However, detecting the emergence of a new research area at an embryonic stage, i.e., before the topic has been consistently labelled by a community of researchers and associated with a number of publications, is still an open challenge.
Blog

AI for the Research Ecosystem workshop #AI4RE – round up
On March 22, 2024, the AI for the Research Ecosystem workshop (#AI4RE) took place in London, kindly hosted by UCL in the wonderful surroundings of Chandler House. The workshop was part of the Turing Institue’s AI UK Fringe series of events which took place around the U.K. The workshop focused on the intersection of the […]
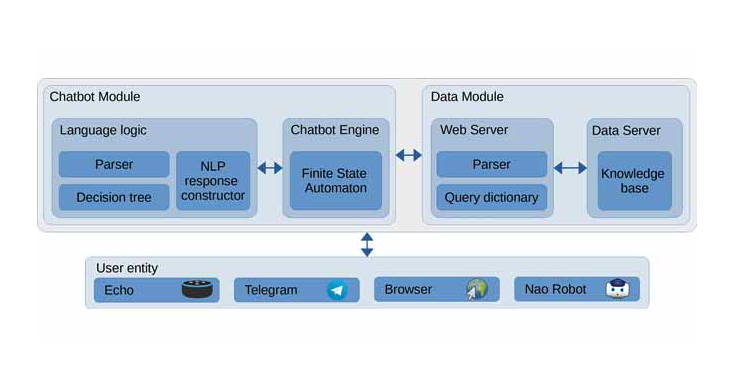
Integrating Conversational Agents and Knowledge Graphs Within the Scholarly Domain
“Integrating Conversational Agents and Knowledge Graphs Within the Scholarly Domain” is a journal paper accepted at IEEE Access. Antonello Meloni1, Simone Angioni1, Angelo Antonio Salatino2, Francesco Osborne2, Diego Reforgiato Recupero1, Enrico Motta2 1 Department of Mathematics and Computer Science, University of Cagliari (Italy) 2 Knowledge Media Institute, The Open University, Milton Keynes (UK) Abstract In […]

R-Classify: Extracting Research Papers’ Relevant Concepts from a Controlled Vocabulary
“R-Classify: Extracting Research Papers’ Relevant Concepts from a Controlled Vocabulary” is a software paper accepted at Software Impacts. Tanay Aggarwal, Angelo Antonio Salatino, Francesco Osborne, Enrico Motta Knowledge Media Institute, The Open University, Milton Keynes (UK) Abstract In the past few decades, we saw a proliferation of scientific articles available online. This data-rich environment offers several opportunities […]

Leveraging Knowledge Graph Technologies to Assess Journals and Conferences at Springer Nature
“Leveraging Knowledge Graph Technologies to Assess Journals and Conferences at Springer Nature” is an In-Use paper presented at the 21st International Semantic Web Conference (ISWC 2022). Simone Angioni1, Angelo Antonio Salatino2, Francesco Osborne2,3,AliaksandrBirukou4, Diego Reforgiato Recupero1, Enrico Motta2 1 Department of Mathematics and Computer Science, University of Cagliari (Italy) 2 Knowledge Media Institute, The Open […]

Best Paper Award at the In-Use Track ISWC 2022
It is an honour to be prized for the Best Paper Award at the In-Use Track ISWC – International Semantic Web Conference (Premiere Conference in the Semantic Web). Great work in collaboration with Springer Nature and UniCa – Università degli Studi di Cagliari. The paper describes our recent efforts in putting semantic technologies (The AIDA […]
Annotating D3 dataset with the CSO Classifier
Abstract The DBLP Discovery Dataset (D3) is a newly created dataset of research papers in the field of Computer Science which can support several tasks like identifying trends in research activity, productivity, focus, bias, accessibility, and impact. This dataset stems from DBLP and integrates additional information from the full-texts. We argue that papers classified with […]

Sci-K 2022 – International Workshop on Scientific Knowledge: Representation, Discovery, and Assessment
“Sci-K 2022 – International Workshop on Scientific Knowledge: Representation, Discovery, and Assessment” is the introductory chapter of the workshop proceedings of “Sci-K 2022 – International Workshop on Scientific Knowledge: Representation, Discovery, and Assessment” co-located with The Web Conference 2022. Paolo Manghi1, Andrea Mannocci1, Francesco Osborne2, Dimitris Sacharidis3, Angelo Salatino2, Thanasis Vergoulis4 1 CNR-ISTI – National […]

Enriching Data Lakes with Knowledge Graphs
“Enriching Data Lakes with Knowledge Graphs” is a workshop paper published at “Knowledge Graph Generation from Text” co-located with ESWC 2022. Alessandro Chessa1,2, Gianni Fenu3, Enrico Motta4, Francesco Osborne4,5, Diego Reforgiato Recupero3,Angelo Antonio Salatino4, Luca Secchi1 1 Linkalab s.r.l., Cagliari, Italy 2 Luiss Data Lab, Rome, Italy 3 University of Cagliari, Cagliari, Italy 4 Knowledge Media Institute, The […]

The AIDA Dashboard: a Web Application for Assessing and Comparing Scientific Conferences
“The AIDA Dashboard: a Web Application for Assessing and Comparing Scientific Conferences” is a research paper submitted to IEEE Access. Simone Angioni1, Angelo Antonio Salatino2, Francesco Osborne2, Diego Reforgiato Recupero1, Enrico Motta2 1 Department of Mathematics and Computer Science, University of Cagliari (Italy) 2 Knowledge Media Institute, The Open University, Milton Keynes (UK) Abstract […]

Characterising Research Areas in the field of AI
“Characterising Research Areas in the field of AI” is a research paper submitted to the special track “Statistical Methods for Science Mapping” on “51st Scientific Meeting of the Italian Statistical Society”. Alessandra Belfiore1, Angelo Salatino2, Francesco Osborne2 1 Università della Campania Luigi Vanvitelli, Caserta (Italy) 2 Knowledge Media Institute, The Open University, Milton Keynes (UK) Abstract […]