On 12th Nov 2020, I have been invited to give a talk to the 5th International School on Applied Probability Theory,
Communications Technologies & Data Science (APTCT-2020), organised and hosted by the RUDN University (Moskow, RU), jointly with Tampere University (Finland) and Brno University of Technology (Czech Republic).
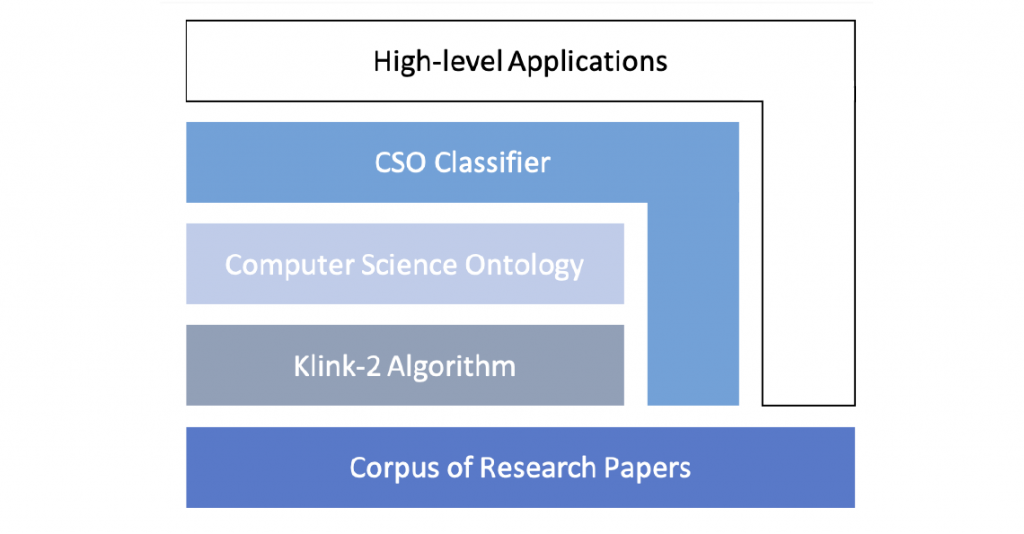
In this lecture, I showed the Computer Science Ontology framework (see Fig. 1), and how it has been successful for us to perform several experiments in the field of Science of Science. Specifically I showed in detail all the 5 layers. I started from the Scholarly data and the big scholarly data sources available out there. Then, I showed the Computer Science Ontology (CSO) and how it has been created: Klink-2 Algorithm. CSO is a large scale ontology of research areas in the field of Computer Science and being an ontology of scientific disciplines it gives the possibility to organise digital libraries (scholarly datasets) according to its constituents (research topics).
Afterwards, I showed the several approaches available for topic classification: connecting scholarly datasets and taxonomies/ontologies of science. As approaches, I showed topic model (e.g. LDA), machine learning approaches (supervised), approaches based on citation networks and finally the CSO Classifier based on Natural Language Processing techniques. The CSO Classifier allows to enhance each research paper in big scholarly dataset with it relevant topics drawn from the CSO ontology.
On top of these 4 initial layers, I showed several high-level applications:
- metadata extraction, showing Smart Topic Miner, a tool used by Springer Nature for annotating and extracting metadata information from book and conference proceedings;
- recommendation of books, showing Smart Book Recommender, a tool developed for Springer Nature to analyse the digital library and select the most appropriate books, journals, and proceedings to market at a scientific event;
- research trends forecast, showing a ML approach able to predict the impact of a topic in industry (receive > 50 patents in the following 10 years);
- conference dashboard, is a recent tool that we developed for assessing conferences across several parameters.
This framework proved to be very successful and we are eager to explore new innovative solutions and contribute to the further development of the Science of Science field.
The lecture was attended by more than 100 students.
Slides
Useful Links
5th International School on Applied Probability Theory, Communications Technologies & Data Science (APTCT-2020): http://www.aptct.ru