
“Leveraging Knowledge Graph Technologies to Assess Journals and Conferences at Springer Nature” is an In-Use paper presented at the 21st International Semantic Web Conference (ISWC 2022). Simone Angioni1, Angelo Antonio Salatino2, Francesco Osborne2,3,AliaksandrBirukou4, Diego Reforgiato Recupero1, Enrico Motta2 1 Department of Mathematics and Computer Science, University of Cagliari (Italy) 2 Knowledge Media Institute, The Open […]
Category: World Wide Web

Best Paper Award at the In-Use Track ISWC 2022
It is an honour to be prized for the Best Paper Award at the In-Use Track ISWC – International Semantic Web Conference (Premiere Conference in the Semantic Web). Great work in collaboration with Springer Nature and UniCa – Università degli Studi di Cagliari. The paper describes our recent efforts in putting semantic technologies (The AIDA […]

Sci-K 2022 – International Workshop on Scientific Knowledge: Representation, Discovery, and Assessment
“Sci-K 2022 – International Workshop on Scientific Knowledge: Representation, Discovery, and Assessment” is the introductory chapter of the workshop proceedings of “Sci-K 2022 – International Workshop on Scientific Knowledge: Representation, Discovery, and Assessment” co-located with The Web Conference 2022. Paolo Manghi1, Andrea Mannocci1, Francesco Osborne2, Dimitris Sacharidis3, Angelo Salatino2, Thanasis Vergoulis4 1 CNR-ISTI – National […]

AIDA: a Knowledge Graph about Research Dynamics in Academia and Industry
“AIDA: a Knowledge Graph about Research Dynamics in Academia and Industry” is a research paper published at the Special Issue on “Scientific Knowledge Graphs and Research Impact Assessment” at Quantitative Science Studies (QSS by MIT Press). Simone Angioni1, Angelo Antonio Salatino2, Francesco Osborne2, Diego Reforgiato Recupero1, Enrico Motta2 1 Department of Mathematics and Computer Science, University […]

The AIDA Dashboard: Analysing Conferences with Semantic Technologies
“The AIDA Dashboard: Analysing Conferences with Semantic Technologies” is a demo paper submitted to the Posters and Demos tracks of the 19th International Semantic Web Conference. Simone Angioni1, Francesco Osborne2, Angelo A. Salatino2, Diego Reforgiato Recupero1, Enrico Motta2 1 University of Cagliari, Via Università 40, 09124 Cagliari 2 Knowledge Media Institute, The Open University, […]
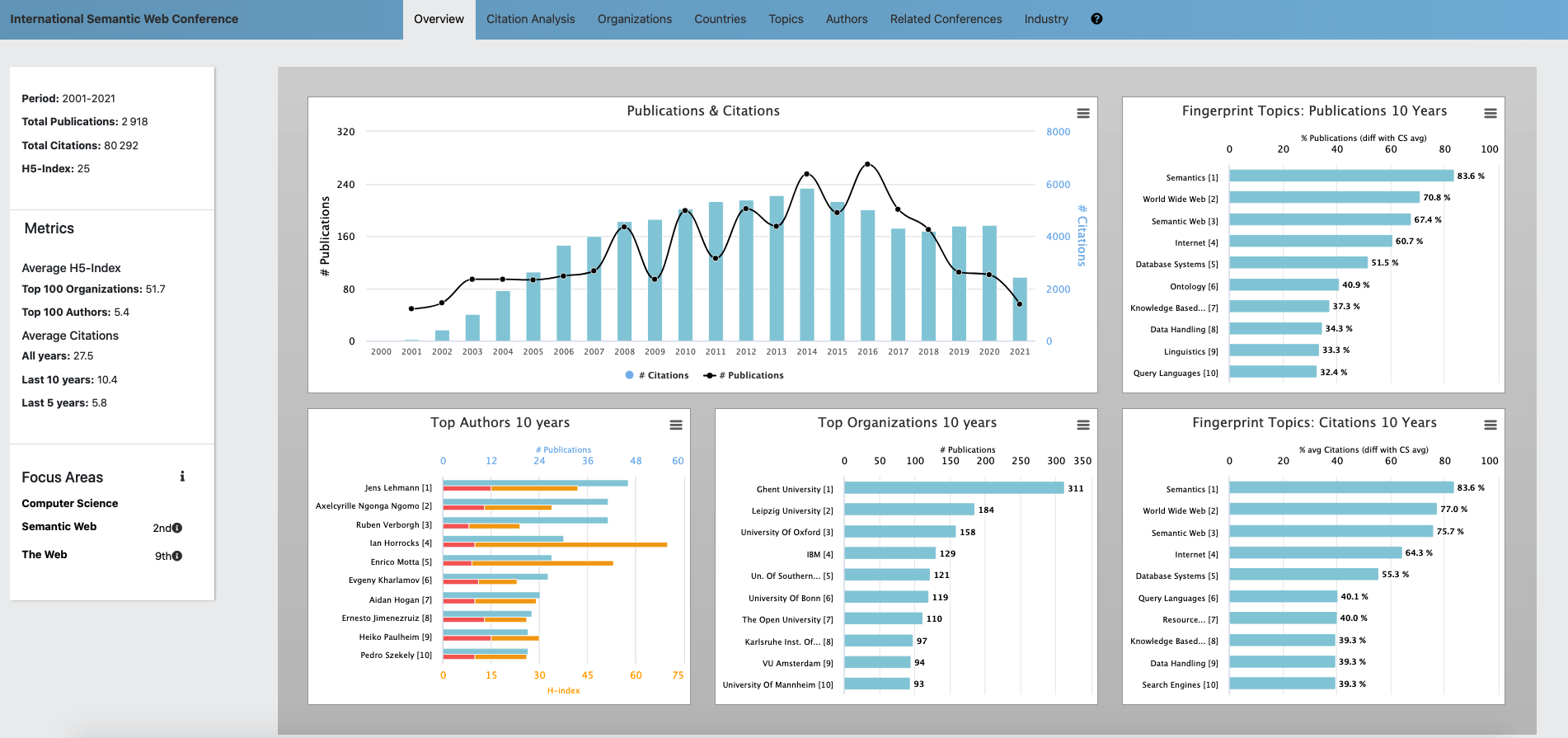
AIDA Dashboard
The AIDA Dashboard is a web application that allows users to visualize several kind of analytics about a specific conference (see Figure 1). The backend is developed in Python, while the frontend is in HTML5 and Javascript. The AIDA Dashboard builds on the Academia/Industry DynAmics knowledge graph (AIDA), a large knowledge base describing 14M articles […]

Academia/Industry DynAmics (AIDA) Knowledge Graph
Academia and industry share a complex, multifaceted, and symbiotic relationship. Analysing the knowledge flow between them, understanding which directions have the biggest potential, and discovering the best strategies to harmonise their efforts is a critical task for several stakeholders. While research publications and patents are an ideal media to analyse this space, current datasets of […]

The Computer Science Ontology: A Comprehensive Automatically-Generated Taxonomy of Research Areas
Ontologies of research areas are important tools for characterising, exploring, and analysing the research landscape. Some fields of research are comprehensively described by large-scale taxonomies, e.g., MeSH in Biology and PhySH in Physics. Conversely, current Computer Science taxonomies are coarse-grained and tend to evolve slowly. For instance, the ACM classification scheme contains only about 2K research topics and the last version dates back to 2012. In this paper, we introduce the Computer Science Ontology (CSO), a large-scale, automatically generated ontology of research areas, which includes about 14K topics and 162K semantic relationships. It was created by applying the Klink-2 algorithm on a very large dataset of 16M scientific articles. CSO presents two main advantages over the alternatives: i) it includes a very large number of topics that do not appear in other classifications, and ii) it can be updated automatically by running Klink-2 on recent corpora of publications. CSO powers several tools adopted by the editorial team at Springer Nature and has been used to enable a variety of solutions, such as classifying research publications, detecting research communities, and predicting research trends. To facilitate the uptake of CSO, we have also released the CSO Classifier, a tool for automatically classifying research papers, and the CSO Portal, a web application that enables users to download, explore, and provide granular feedback on CSO. Users can use the portal to navigate and visualise sections of the ontology, rate topics and relationships, and suggest missing ones. The portal will support the publication of and access to regular new releases of CSO, with the aim of providing a comprehensive resource to the various research communities engaged with scholarly data.
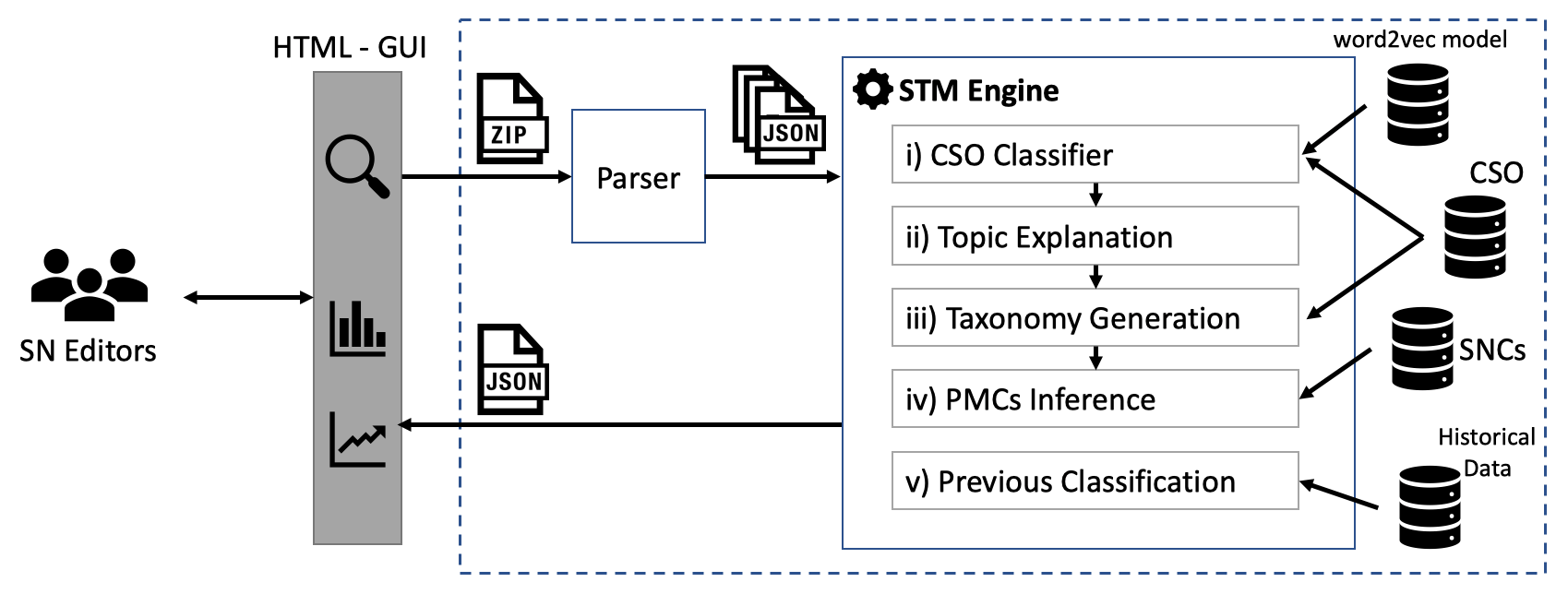
Improving Editorial Workflow and Metadata Quality at Springer Nature
Identifying the research topics that best describe the scope of a scientific publication is a crucial task for editors, in particular because the quality of these annotations determine how effectively users are able to discover the right content in online libraries. For this reason, Springer Nature, the world’s largest academic book publisher, has traditionally entrusted this task to their most expert editors. These editors manually analyse all new books, possibly including hundreds of chapters, and produce a list of the most relevant topics. Hence, this process has traditionally been very expensive, time-consuming, and confined to a few senior editors. For these reasons, back in 2016 we developed Smart Topic Miner (STM), an ontology-driven application that assists the Springer Nature editorial team in annotating the volumes of all books covering conference proceedings in Computer Science. Since then STM has been regularly used by editors in Germany, China, Brazil, India, and Japan, for a total of about 800 volumes per year. Over the past three years the initial prototype has iteratively evolved in response to feedback from the users and evolving requirements.

The World Wide Web turns 30
I have always been passionate about technology. When I bought my first computer (special thanks to my father for funding it), and got it connected to the internet, it soon became part of my life: downloading movies, music, studying, chatting, engaging with different communities, writing a blog, buying and selling stuff. The web gave me […]