
“CSO Classifier 3.0: A Scalable Unsupervised Method for Classifying Documents in Terms of Research Topics” is a journal paper accepted at the Special Issue of “TPDL 2019 & 2020” at Scientometrics. Angelo Salatino, Francesco Osborne, Enrico Motta Abstract Classifying scientific articles, patents, and other documents according to the relevant research topics is an important task, […]
Tag: Text Mining

How to use the CSO Classifier in other domains
Being able to characterise research papers according to their topics enables a multitude of high-level applications such as i) categorise proceedings in digital libraries, ii) semantically enhance the metadata of scientific publications, iii) generate recommendations, iv) produce smart analytics, v) detect research trends, and others.
In our recent work, we designed and developed an unsupervised approach to automatically classify research papers according to an ontology of research areas in the field of Computer Science. This approach uses well-known technologies from the field of Natural Language Processing which makes it easily generalisable. In this article, we will show how we can customise the CSO Classifier and apply it to other fields of Science.

The CSO Classifier: Ontology-Driven Detection of Research Topics in Scholarly Articles
Classifying research papers according to their research topics is an important task to improve their retrievability, assist the creation of smart analytics, and support a variety of approaches for analysing and making sense of the research environment. In this paper, we present the CSO Classifier, a new unsupervised approach for automatically classifying research papers according to the Computer Science Ontology (CSO), a comprehensive ontology of research areas in the field of Computer Science. The CSO Classifier takes as input the metadata associated with a research paper (title, abstract, keywords) and returns a selection of research concepts drawn from the ontology. The approach was evaluated on a gold standard of manually annotated articles yielding a significant improvement over alternative methods.
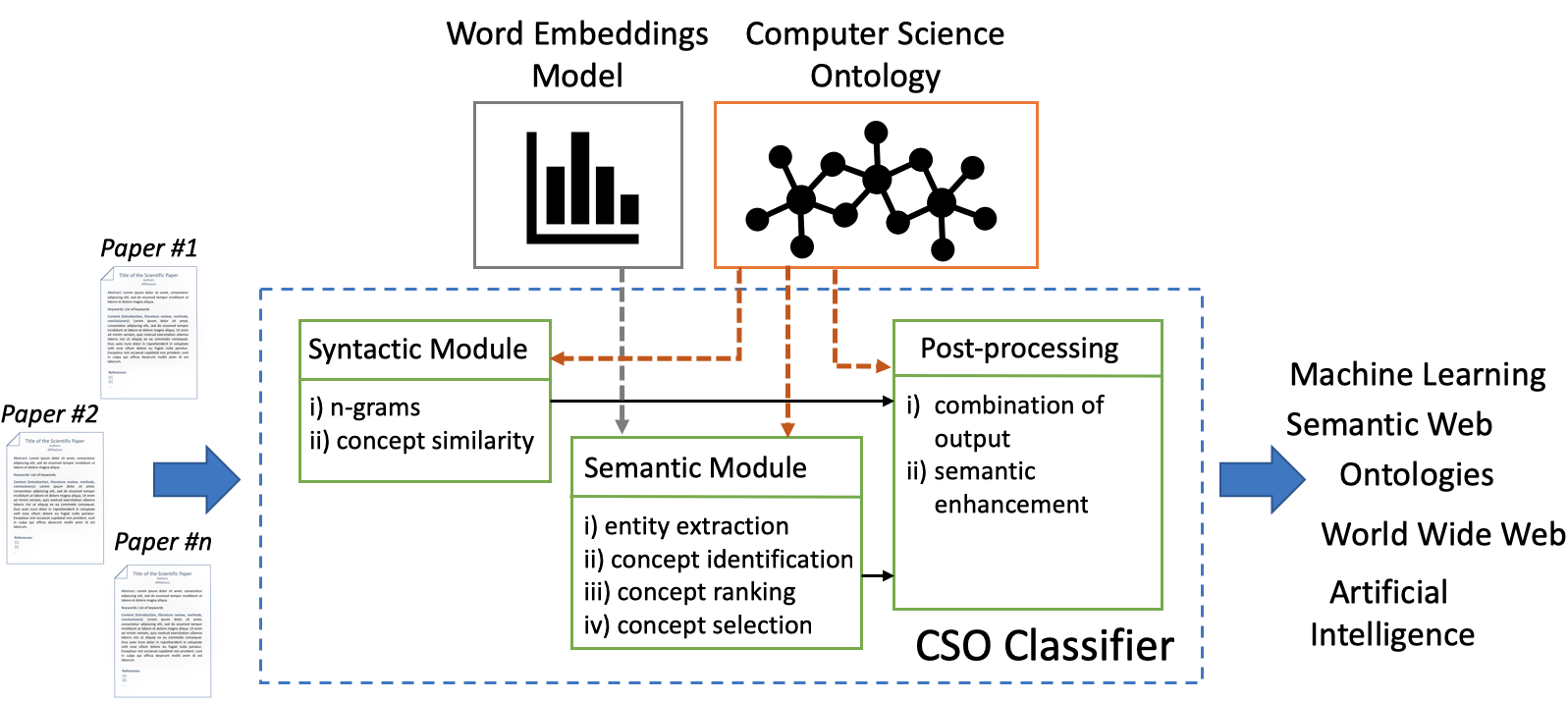
New release: CSO Classifier v2.1
We are pleased to announce that we recently created a new release of the CSO Classifier (v2.1), an application for automatically classifying research papers according to the Computer Science Ontology (CSO). Recently, we have been intensively working on improving its scalability, removing all its bottlenecks and making sure it could be run on large corpus. […]

CSO Classifier
Classifying research papers according to their research topics is an important task to improve their retrievability, assist the creation of smart analytics, and support a variety of approaches for analysing and making sense of the research environment. In this page, we present the CSO Classifier, a new unsupervised approach for automatically classifying research papers according to the Computer Science Ontology (CSO), a comprehensive ontology of research areas in the field of Computer Science.

Classifying Research Papers with the Computer Science Ontology
The CSO Classifier is an application for automatically classifying academic papers according to the rich taxonomy of topics from CSO. The aim is to facilitate the adoption of CSO across the various communities engaged with scholarly data and to foster the development of new applications based on this knowledge base.

Supporting Editorial Activities at Springer Nature
The project aims at fostering Springer Nature editorial activities by supporting them with a variety of smart solutions leveraging artificial intelligence, data mining, and semantic technologies. In particular, the KMi team will support Springer Nature editorial team in classifying proceedings and other editorial products, taking informed decisions about their marketing strategy, and improve their internal classification.