
“R-Classify: Extracting Research Papers’ Relevant Concepts from a Controlled Vocabulary” is a software paper accepted at Software Impacts. Tanay Aggarwal, Angelo Antonio Salatino, Francesco Osborne, Enrico Motta Knowledge Media Institute, The Open University, Milton Keynes (UK) Abstract In the past few decades, we saw a proliferation of scientific articles available online. This data-rich environment offers several opportunities […]
Category: Semantic Web

Leveraging Knowledge Graph Technologies to Assess Journals and Conferences at Springer Nature
“Leveraging Knowledge Graph Technologies to Assess Journals and Conferences at Springer Nature” is an In-Use paper presented at the 21st International Semantic Web Conference (ISWC 2022). Simone Angioni1, Angelo Antonio Salatino2, Francesco Osborne2,3,AliaksandrBirukou4, Diego Reforgiato Recupero1, Enrico Motta2 1 Department of Mathematics and Computer Science, University of Cagliari (Italy) 2 Knowledge Media Institute, The Open […]

Best Paper Award at the In-Use Track ISWC 2022
It is an honour to be prized for the Best Paper Award at the In-Use Track ISWC – International Semantic Web Conference (Premiere Conference in the Semantic Web). Great work in collaboration with Springer Nature and UniCa – Università degli Studi di Cagliari. The paper describes our recent efforts in putting semantic technologies (The AIDA […]

Sci-K 2022 – International Workshop on Scientific Knowledge: Representation, Discovery, and Assessment
“Sci-K 2022 – International Workshop on Scientific Knowledge: Representation, Discovery, and Assessment” is the introductory chapter of the workshop proceedings of “Sci-K 2022 – International Workshop on Scientific Knowledge: Representation, Discovery, and Assessment” co-located with The Web Conference 2022. Paolo Manghi1, Andrea Mannocci1, Francesco Osborne2, Dimitris Sacharidis3, Angelo Salatino2, Thanasis Vergoulis4 1 CNR-ISTI – National […]

The AIDA Dashboard: a Web Application for Assessing and Comparing Scientific Conferences
“The AIDA Dashboard: a Web Application for Assessing and Comparing Scientific Conferences” is a research paper submitted to IEEE Access. Simone Angioni1, Angelo Antonio Salatino2, Francesco Osborne2, Diego Reforgiato Recupero1, Enrico Motta2 1 Department of Mathematics and Computer Science, University of Cagliari (Italy) 2 Knowledge Media Institute, The Open University, Milton Keynes (UK) Abstract […]

Characterising Research Areas in the field of AI
“Characterising Research Areas in the field of AI” is a research paper submitted to the special track “Statistical Methods for Science Mapping” on “51st Scientific Meeting of the Italian Statistical Society”. Alessandra Belfiore1, Angelo Salatino2, Francesco Osborne2 1 Università della Campania Luigi Vanvitelli, Caserta (Italy) 2 Knowledge Media Institute, The Open University, Milton Keynes (UK) Abstract […]

New trends in scientific knowledge graphs and research impact assessment
“New trends in scientific knowledge graphs and research impact assessment” is the introductory chapter of the Special Issue on “Scientific Knowledge Graphs and Research Impact Assessment” at Quantitative Science Studies (QSS by MIT Press). Paolo Manghi1, Andrea Mannocci1, Francesco Osborne2, Dimitris Sacharidis3, Angelo Salatino2, Thanasis Vergoulis4 1 CNR-ISTI – National Research Council, Institute of Information Science […]

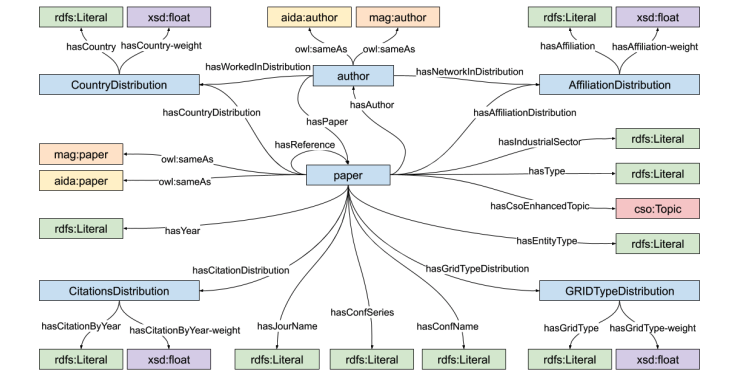
AIDA: a Knowledge Graph about Research Dynamics in Academia and Industry
“AIDA: a Knowledge Graph about Research Dynamics in Academia and Industry” is a research paper published at the Special Issue on “Scientific Knowledge Graphs and Research Impact Assessment” at Quantitative Science Studies (QSS by MIT Press). Simone Angioni1, Angelo Antonio Salatino2, Francesco Osborne2, Diego Reforgiato Recupero1, Enrico Motta2 1 Department of Mathematics and Computer Science, University […]

Assessing Scientific Conferences through Knowledge Graphs
“Assessing Scientific Conferences through Knowledge Graphs” is a paper published at the Industry Track of the 2021 International Semantic Web Conference. Simone Angioni1, Angelo Antonio Salatino2, Francesco Osborne2, Aliaksandr Birukou3, Diego Reforgiato Recupero1, Enrico Motta2 1 Department of Mathematics and Computer Science, University of Cagliari (Italy) 2 Knowledge Media Institute, The Open University, Milton Keynes (UK) […]
Link Prediction of Weighted Triples for Knowledge Graph Completion Within the Scholarly Domain
“Link Prediction of Weighted Triples for Knowledge Graph Completion Within the Scholarly Domain” is a journal paper accepted at IEEE Access Mojtaba Nayyeri1,2, Gökce Müge Cil1, Sahar Vahdati2, Francesco Osborne3, Andrey Kravchenko4, Simone Angioni5, Angelo Salatino3, Diego Reforgiato Recupero5, Enrico Motta3, Jens Lehmann1,6 1 SDA Research Group, University of Bonn, 53115 Bonn, Germany 2 […]