
“Sci-K 2022 – International Workshop on Scientific Knowledge: Representation, Discovery, and Assessment” is the introductory chapter of the workshop proceedings of “Sci-K 2022 – International Workshop on Scientific Knowledge: Representation, Discovery, and Assessment” co-located with The Web Conference 2022. Paolo Manghi1, Andrea Mannocci1, Francesco Osborne2, Dimitris Sacharidis3, Angelo Salatino2, Thanasis Vergoulis4 1 CNR-ISTI – National […]
Category: Machine Learning

Enriching Data Lakes with Knowledge Graphs
“Enriching Data Lakes with Knowledge Graphs” is a workshop paper published at “Knowledge Graph Generation from Text” co-located with ESWC 2022. Alessandro Chessa1,2, Gianni Fenu3, Enrico Motta4, Francesco Osborne4,5, Diego Reforgiato Recupero3,Angelo Antonio Salatino4, Luca Secchi1 1 Linkalab s.r.l., Cagliari, Italy 2 Luiss Data Lab, Rome, Italy 3 University of Cagliari, Cagliari, Italy 4 Knowledge Media Institute, The […]
Link Prediction of Weighted Triples for Knowledge Graph Completion Within the Scholarly Domain
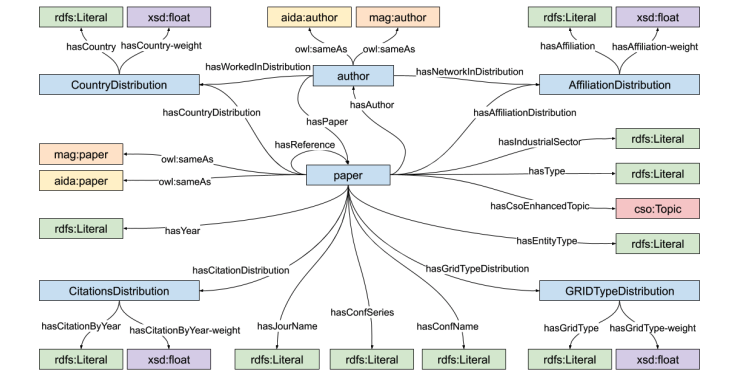
“Link Prediction of Weighted Triples for Knowledge Graph Completion Within the Scholarly Domain” is a journal paper accepted at IEEE Access Mojtaba Nayyeri1,2, Gökce Müge Cil1, Sahar Vahdati2, Francesco Osborne3, Andrey Kravchenko4, Simone Angioni5, Angelo Salatino3, Diego Reforgiato Recupero5, Enrico Motta3, Jens Lehmann1,6 1 SDA Research Group, University of Bonn, 53115 Bonn, Germany 2 […]

Applying Machine Learning Techniques to Big Data in the Scholarly Domain
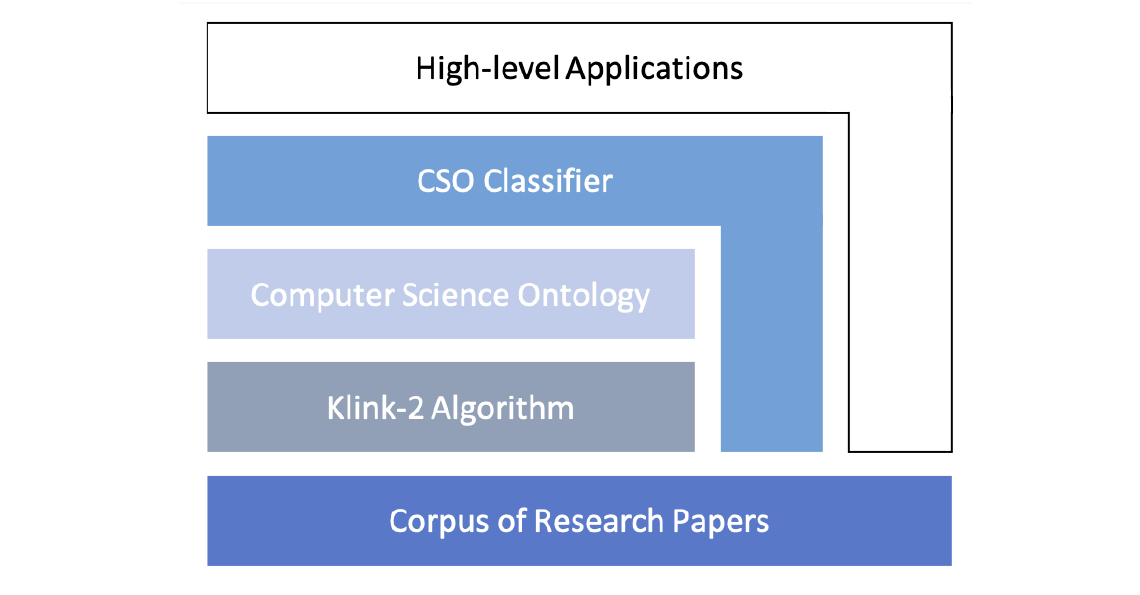
Ontologies of research areas have been proven to be useful in many application for analysing and making sense of scholarly data. In this lecture, I will present how we produced the Computer Science Ontology (CSO), which is the largest ontology of research areas in the field of Computer Science, and discuss a number of applications that build on CSO, to support high-level tasks, such as topic classification, research trends forecasting, metadata extraction, and recommendation of books.
Ontology Extraction and Usage in the Scholarly Knowledge Domain
Ontologies of research areas have been proven to be useful in many application for analysing and making sense of scholarly data. In this chapter, we present the Computer Science Ontology (CSO), which is the largest ontology of research areas in the field of Computer Science, and discuss a number of applications that build on CSO, to support high-level tasks, such as topic classification, metadata extraction, and recommendation of books.
1st Workshop on Scientific Knowledge Graphs (SKG2020)
In the last decade, we experienced an urgent need for a flexible, context-sensitive, fine-grained, and machine-actionable representation of scholarly knowledge and corresponding infrastructures for knowledge curation, publishing and processing. Such technical infrastructures are becoming increasingly popular in representing scholarly knowledge as structured, interlinked, and semantically rich Scholarly Knowledge Graphs (SKG).
The 1st Workshop on Scientific Knowledge Graphs (SKG2020) aims at bringing together researchers and practitioners from different fields (including, but not limited to, Digital Libraries, Information Extraction, Machine Learning, Semantic Web, Knowledge Engineering, Natural Language Processing, Scholarly Communication, and Bibliometrics) in order to explore innovative solutions and ideas for the production and consumption of Scientific Knowledge Graphs (SKGs).

1st Smart City and Robotic Challenge (SCiRoC 2019)
Last week — 18th to 21st September 2019 — the first International Competition on Smart Cities and Robotics took place in Milton Keynes (UK). Different teams from Spain, UK, Germany, France, Portugal and others took part in this competition. As the name suggests, SCiRoC aims at bringing robots in the context of smart cities. Indeed, their primary objective was to interact both with smart cities infrastructures, such as the MK Data Hub, and citizens.
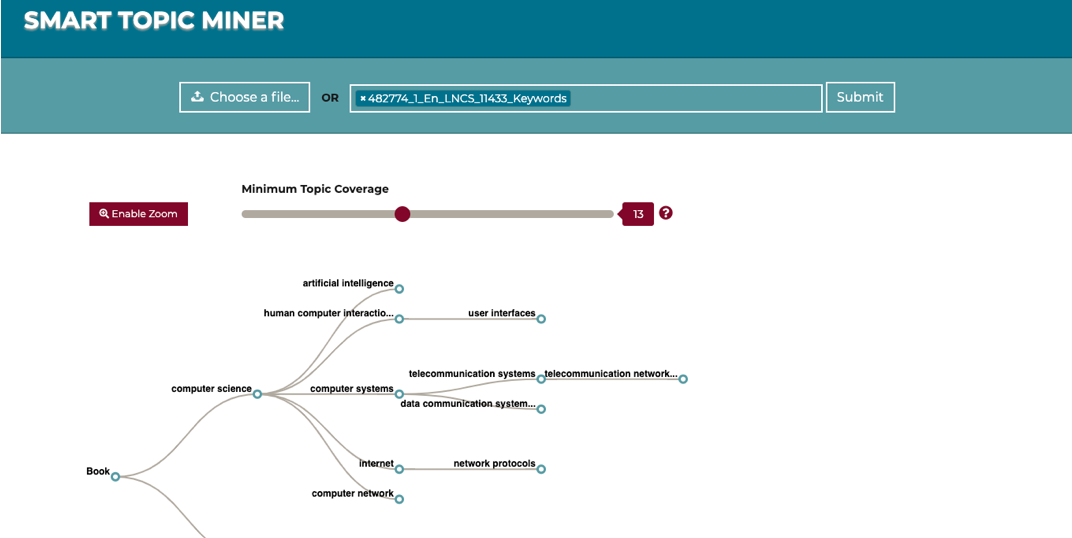
Smart Topics Miner 2: Improving Proceedings Retrievability at Springer Nature
Producing a robust and comprehensive representation of the research topics covered by a scientific publication is a crucial task that has a major impact on its retrievability and consequently on the diffusion of the relevant scientific ideas. Springer Nature, the world’s largest academic book publisher, has typically entrusted this task to the most expert editors, which had to manually analyse new books and produce a list of the most relevant topics. To support Springer Nature in this task, we developed Smart Topic Miner, an application that assists the editorial team in annotating proceedings books according to a large-scale ontology of research areas. Over the past three years, we evolved this application according to the editors’ feedback and developed a new engine, a new interface, and several other functionalities. In this demo paper, we present Smart Topic Miner 2, the most recent version of the tool, which is being regularly utilized by editors in Germany, China, Brazil, and Japan to annotate all book series covering conference proceedings in Computer Science, for a total of about 800 volumes per year.
Springer Nature Hack Day – Berlin
On 26-27 April 2018, Francesco Osborne and I attended the third edition of the Springer Nature Hack Day, which was held in its headquarter in Berlin. The Springer Nature Hack Day is an event that allows researchers, developers, tech companies, and Springer Nature itself, to gather together and tackle current research issues. Offering also opportunities […]

2100 AI: Reflections on the mechanisation of scientific discovery
“2100 AI: Reflections on the mechanisation of scientific discovery” is a paper submitted to the RE-CODING BLACK MIRROR Workshop co-located with the International Semantic Web Conference (ISWC) 2017, 21-25 October 2017, Vienna, Austria. Authors Andrea Mannocci, Angelo Salatino, Francesco Osborne and Enrico Motta Abstract The pace of nowadays research is hectic. Datasets and papers are […]