
“Characterising Research Areas in the field of AI” is a research paper submitted to the special track “Statistical Methods for Science Mapping” on “51st Scientific Meeting of the Italian Statistical Society”. Alessandra Belfiore1, Angelo Salatino2, Francesco Osborne2 1 Università della Campania Luigi Vanvitelli, Caserta (Italy) 2 Knowledge Media Institute, The Open University, Milton Keynes (UK) Abstract […]
Category: Network Science

Trans4E: Link Prediction on Scholarly Knowledge Graphs
“Trans4E: Link Prediction on Scholarly Knowledge Graphs” is a journal paper submitted to the Special Issue on “Knowledge Graph Representation & Reasoning” at the Neurocomputing Journal Mojtaba Nayyeria, Gokce Muge Cila, Sahar Vahdatib, Francesco Osborned, Mahfuzur Rahmana,Simone Angionie, Angelo Salatinod, Diego Reforgiato Recuperoe, Nadezhda Vassilyevaa, Enrico Mottad and Jens Lehmanna,c aSDA Research Group, University […]

Scientific Knowledge Graphs: an Overview
On 12th May 2021, I have been invited by Dimitris Sacharidis to give a lecture to the master course is INFO-H509 “XML and Web Technologies” at the Université Libre de Bruxelles. Abstract In the last decade, several Scientific Knowledge Graphs (SKG) were released, representing scientific knowledge in a structured, interlinked, and semantically rich manner. But, what […]
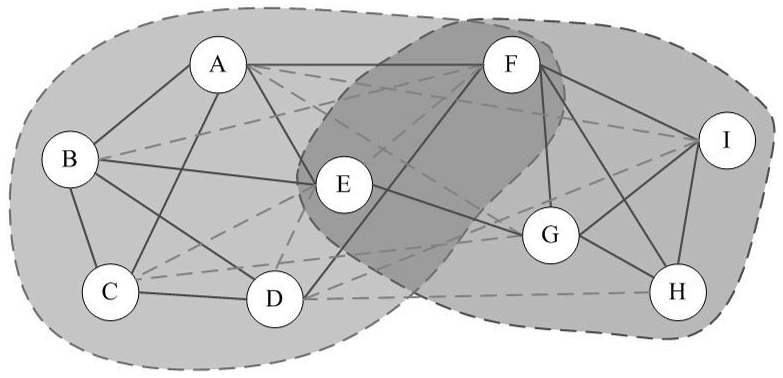
Clique Percolation Method in Python
Clique Percolation Method (CPM) is an algorithm for finding overlapping communities within networks, introduced by Palla et al. (2005, see references). This implementation in Python, firstly detects communities of size k, then creates a clique graph. Each community will be represented by each connected component in the clique graph. Algorithm The algorithm performs the following […]

Applying Machine Learning Techniques to Big Data in the Scholarly Domain
Ontologies of research areas have been proven to be useful in many application for analysing and making sense of scholarly data. In this lecture, I will present how we produced the Computer Science Ontology (CSO), which is the largest ontology of research areas in the field of Computer Science, and discuss a number of applications that build on CSO, to support high-level tasks, such as topic classification, research trends forecasting, metadata extraction, and recommendation of books.

Integrating Knowledge Graphs for Analysing Academia and Industry Dynamics
Academia and industry are constantly engaged in a joint effort for producing scientific knowledge that will shape the society of the future. Analysing the knowledge flow between them and understanding how they influence each other is a critical task for researchers, governments, funding bodies, investors, and companies. However, current corpora are unfit to support large-scale analysis of the knowledge flow between academia and industry since they lack of a good characterization of research topics and industrial sectors. In this short paper, we introduce the Academia/Industry DynAmics (AIDA) Knowledge Graph, which characterizes 14M papers and 8M patents according to the research topics drawn from the Computer Science Ontology. 4M papers and 5M patents are also classified according to the type of the author’s affiliations (academy, industry, or collaborative) and 66 industrial sectors (e.g., automotive, financial, energy, electronics) obtained from DBpedia. AIDA was generated by an automatic pipeline that integrates several knowledge graphs and bibliographic corpora, including Microsoft Academic Graph, Dimensions, English DBpedia, the Computer Science Ontology, and the Global Research Identifier Database.
1st Workshop on Scientific Knowledge Graphs (SKG2020)
In the last decade, we experienced an urgent need for a flexible, context-sensitive, fine-grained, and machine-actionable representation of scholarly knowledge and corresponding infrastructures for knowledge curation, publishing and processing. Such technical infrastructures are becoming increasingly popular in representing scholarly knowledge as structured, interlinked, and semantically rich Scholarly Knowledge Graphs (SKG).
The 1st Workshop on Scientific Knowledge Graphs (SKG2020) aims at bringing together researchers and practitioners from different fields (including, but not limited to, Digital Libraries, Information Extraction, Machine Learning, Semantic Web, Knowledge Engineering, Natural Language Processing, Scholarly Communication, and Bibliometrics) in order to explore innovative solutions and ideas for the production and consumption of Scientific Knowledge Graphs (SKGs).
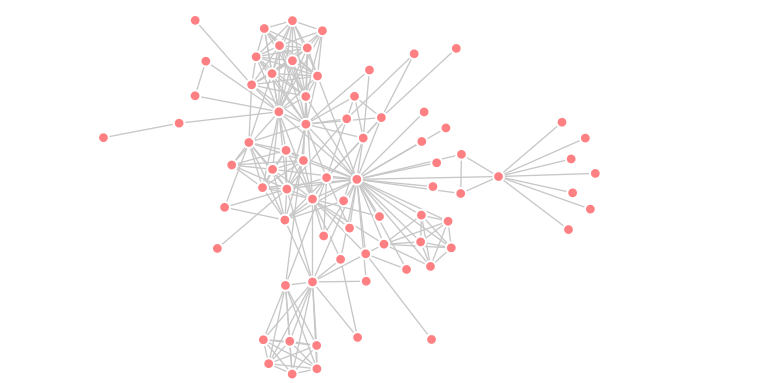
Are citation networks really acyclic?
Simple answer: no. However, before getting into a more detailed answer, allow me to briefly introduce the concept of citation networks, then I will describe why citation networks cannot be considered acyclic anymore. In the scholarly domain, citation networks is an information network in which each node represents a scientific paper and a link between […]

Springer Nature Video of Berlin’s Hack Day
Last April, with my team, we attended the Springer Nature HackDay in Berlin (here is the post). Recently, Springer Nature released a short video featuring us. Summarised is also my interview, in which I discuss my research project and why we think SciGraph is important for those who work in the field of Science of Science. […]

Invited Talk – Early detection of Research Topics
On 2nd of August 2018, I have been invited by Boris Veytsman, Principal Research Scientist at Chan Zuckerberg Initiative (formerly Meta), to give a talk about my PhD work. Differently from my previous talk to the ORNL group, I had the opportunity to describe my doctoral work more comprehensively. More specifically, I initially showed what is available […]