On 26-27 April 2018, Francesco Osborne and I attended the third edition of the Springer Nature Hack Day, which was held in its headquarter in Berlin.
The Springer Nature Hack Day is an event that allows researchers, developers, tech companies, and Springer Nature itself, to gather together and tackle current research issues. Offering also opportunities for potential collaborations and networking.
This was my second time attending a hack day organised by Springer Nature. Indeed, with my colleagues Andrea Mannocci and Thiviyan Thanapalasingam, we attended the previous edition, back in November 2017, working on a Venue-centric trends project (read full story here). An extended version of this project has then been presented at the SAVE-SD workshop co-located with The Web Conference 2018 [1].
In this edition, the participants pitched six different ideas and projects, centred around “analytics and metrics to measure the impact of science”, such as: Disease Dashboard, Hot Topics (our project), Keyword Recommendation, Data mining for historians, Search-Assist, and Semantic Entity Marker. More information about the whole event can be found in this Springer Nature blog post.
With the “Hot Topics” project, we wanted to understand what is the focus of Innovation in the Tech Industry? In particular, based on the papers downloaded by tech companies, in the period 2015-17, we performed an analysis of their content to understand which research topics, most of the tech companies, were interested in (research trend analysis). Also, based on the paper metadata, for a given research topic we suggested prominent journals, organizations and authors. This study provides a number of advantages, such as:
- Providing better service to Springer Nature industry customers
- Providing inspiration to editors to focus on publishing more on the key topics
- Understanding the impact of science in industry and media
- Bridging industry and academy by suggesting collaboration with expert and organizations
Our team was composed by Anne Lauscher, Angelo Salatino, Francesco Osborne, Jenny Cardenas-Osorio, Thomas Scheidsteger, Jochen Teufel, Eva Volná, Aman Bhardwaj, and Chris Bendall.
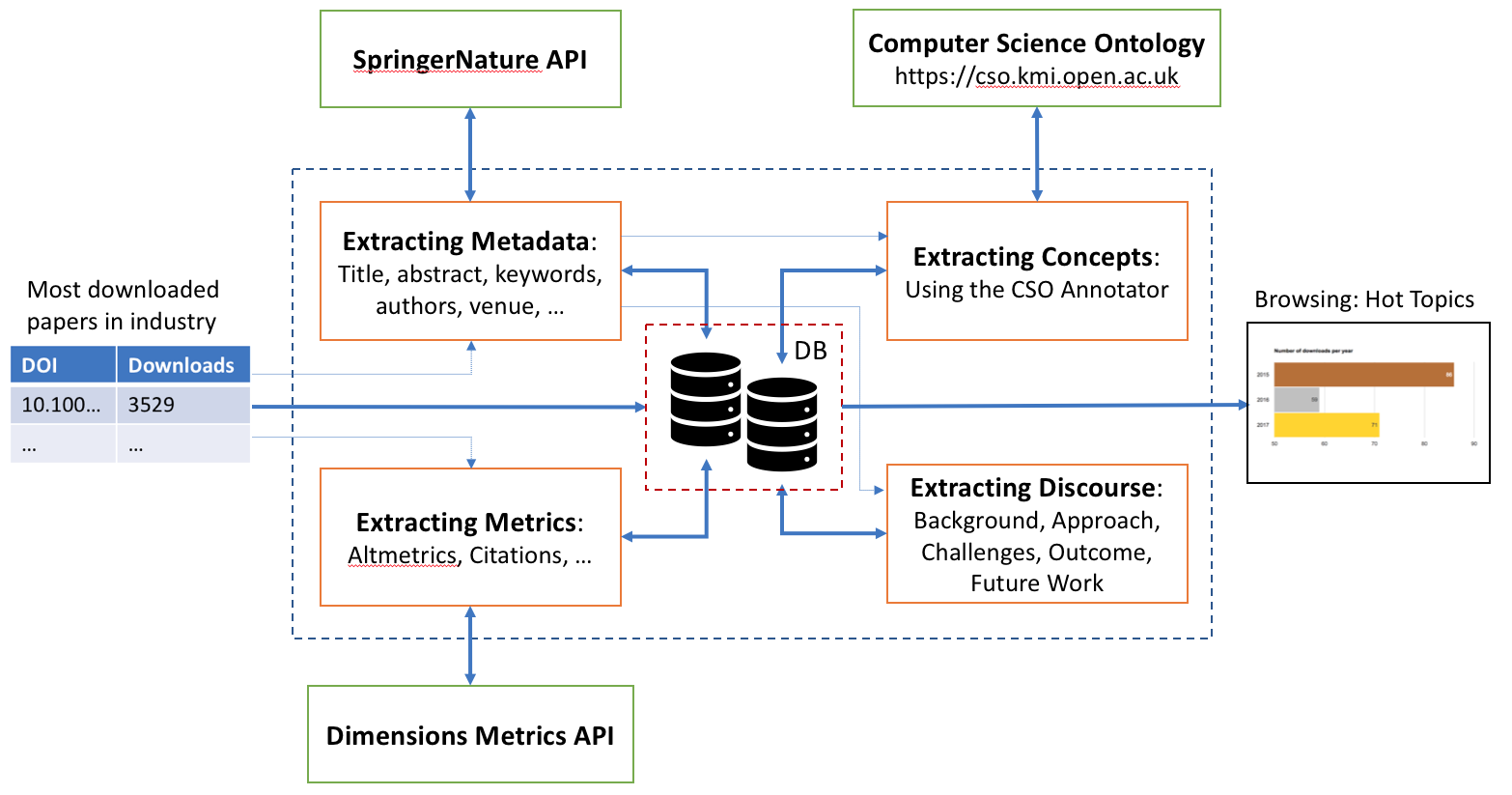
Our starting point was a dataset containing a set of papers, referred only through their DOI, and the amount of times they have been downloaded by tech companies in the years 2015, 2016 and 2017. We then organised our project around four main components, cooperating together to produce a wider dataset. Here we associated each paper with more metrics and metadata. In addition, we also developed a user interface for browsing the different research trends. Figure 1 provides an overview of the project.
The first component is the metadata extraction. For each paper, we used its DOI to download further metadata querying Springer Nature database through their API. This metadata include title, abstract, keywords, authors, venue and other relevant information. Next, within the concept extraction module, for each paper we determined research topics using the CSO Annotator over their previously downloaded abstract, title and keywords. The CSO Annotator is a piece of software, written in Python, that analyses a piece of text and is able to annotate the content with the research topics included in the Computer Science Ontology (CSO).
With the third component, for each paper, we extracted a set of metrics aiming at completing the already downloaded metadata. For a given DOI, we queried the Dimension Metrics API to retrieve Altmetrics and number of Citations.
Lastly, in the discourse extraction module we use some Natural Language Processing (NLP) techniques to detect specific expressions which reflect the scientific discourse. Using the abstract, we focused on discourses around background, approach, challenges, outcome and future work.
All this data and information about papers are then aggregated per research topic.
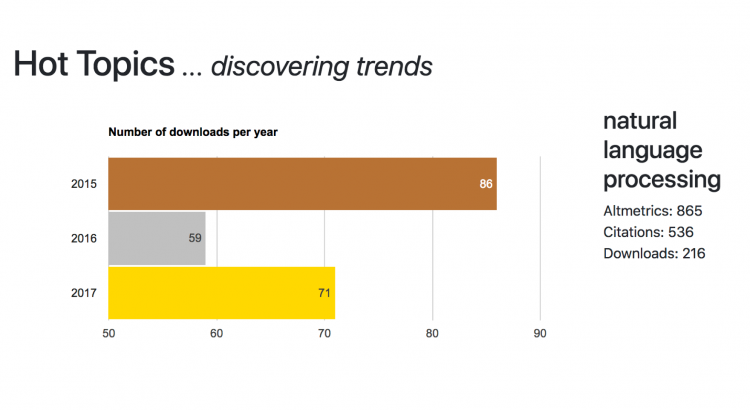
The final outcome of this project is a working prototype that allows to analyse and explore the dynamics of research topics in industry, academia and social media. In particular, we developed a web page, that for a given research topics, it shows the usage statistics over the years (2015-17) by tech industries, a list of top-tier journals, prominent organisations and experts. In addition, it shows a number of metrics correlated with the online presence of topics (Altmetrics), number of citations, trend analysis of subtopics, and discourse element analysis.
In conclusion, we are highly satisfied by the outcome of this hack day, considering what we achieved within the amount of time at our disposal. The project itself gave us satisfactory results which also allowed us to be among the winners of the competition.
Considering the results and the importance of such project, we will keep working on it, potentially with all the members of the team, to make this prototype a real product for Springer Nature.
Important links:
GitHub Repository of the Project: https://github.com/angelosalatino/SN_HackDay-Berlin2018
CSO Annotator: https://github.com/angelosalatino/cso-annotator
Computer Science Ontology: https://cso.kmi.open.ac.uk
SN Hack Day Round-up: Analytics and Metrics: https://researchdata.springernature.com/users/82895-sn-scigraph/posts/32945-sn-hack-day-round-up-analytics-and-metrics
References:
[1] Andrea Mannocci, Francesco Osborne and Enrico Motta (2018): Geographical trends in research: a preliminary analysis on authors’ affiliations. Read here: https://save-sd.github.io/2018/accepted/mannocci/index.pdf
Media:
Coding coding and coding! Converting food and coffee in machine language!! @SpringerNature #SN_HackDay #ScholarlyData It’s nice to see different ideas becoming a prototype.. Looking forward to see the results later today. pic.twitter.com/j3IZv1R2fs
— Angelo A. Salatino (@angelosalatino) 27 April 2018