
On 2nd of August 2018, I have been invited by Boris Veytsman, Principal Research Scientist at Chan Zuckerberg Initiative (formerly Meta), to give a talk about my PhD work. Differently from my previous talk to the ORNL group, I had the opportunity to describe my doctoral work more comprehensively. More specifically, I initially showed what is available […]
Category: Artificial Intelligence

Invited Talk – AUGUR: Forecasting the Emergence of New Research Topics
On 30th Jul 2018, I have been invited from Dasha Herrmannova, former PhD student at the KMi, to give a talk at the “Machine Learning and Graph Mining for Big Scholarly Data” workshop organised for the Computational Data Analytics Group at Oak Ridge National Laboratory (ORNL). In this talk, named “AUGUR: Forecasting the Emergence of New […]

Classifying Research Papers with the Computer Science Ontology
The CSO Classifier is an application for automatically classifying academic papers according to the rich taxonomy of topics from CSO. The aim is to facilitate the adoption of CSO across the various communities engaged with scholarly data and to foster the development of new applications based on this knowledge base.
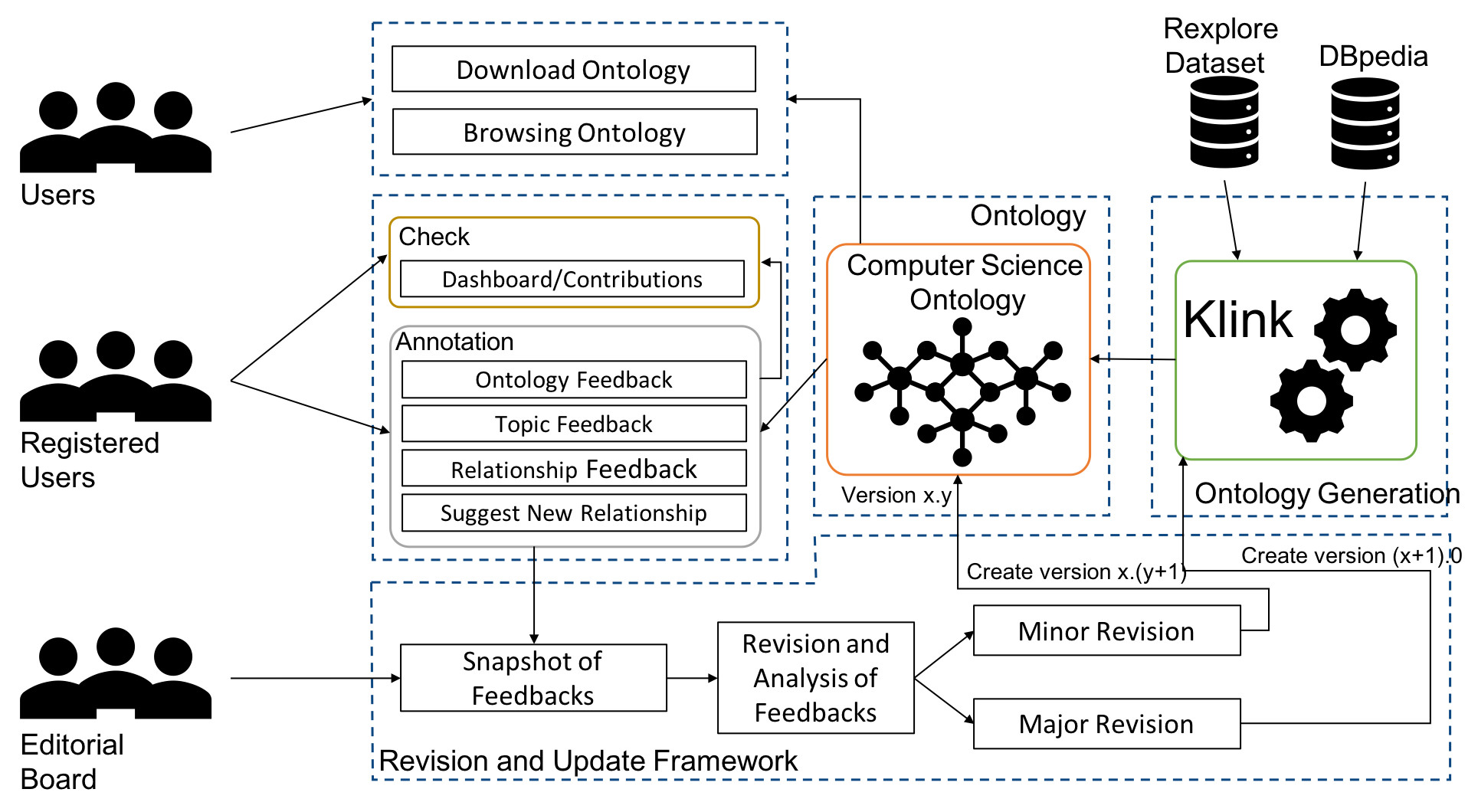
The Computer Science Ontology: A Large-Scale Taxonomy of Research Areas
Ontologies of research areas are important tools for characterising, exploring, and analysing the research landscape. Some fields of research are comprehensively described by large-scale taxonomies, e.g., MeSH in Biology and PhySH in Physics. Conversely, current Computer Science taxonomies are coarse-grained and tend to evolve slowly. For instance, the ACM classification scheme contains only about 2K research topics and the last version dates back to 2012. In this paper, we introduce the Computer Science Ontology (CSO), a large-scale, automatically generated ontology of research areas, which includes about 26K topics and 226K semantic relationships. It was created by applying the Klink-2 algorithm on a very large dataset of 16M scientific articles.
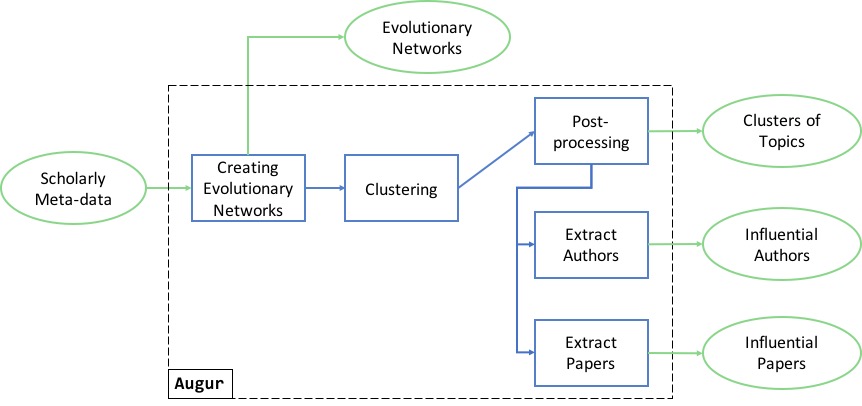
AUGUR: Forecasting the Emergence of New Research Topics
“AUGUR: Forecasting the Emergence of New Research Topics” is a paper submitted to the ACM/IEEE Joint Conference on Digital Libraries 2018, presented on June 5 2018, in Fort Worth, TX, USA Angelo Salatino, Francesco Osborne and Enrico Motta Abstract Being able to rapidly recognise new research trends is strategic for many stakeholders, including universities, […]
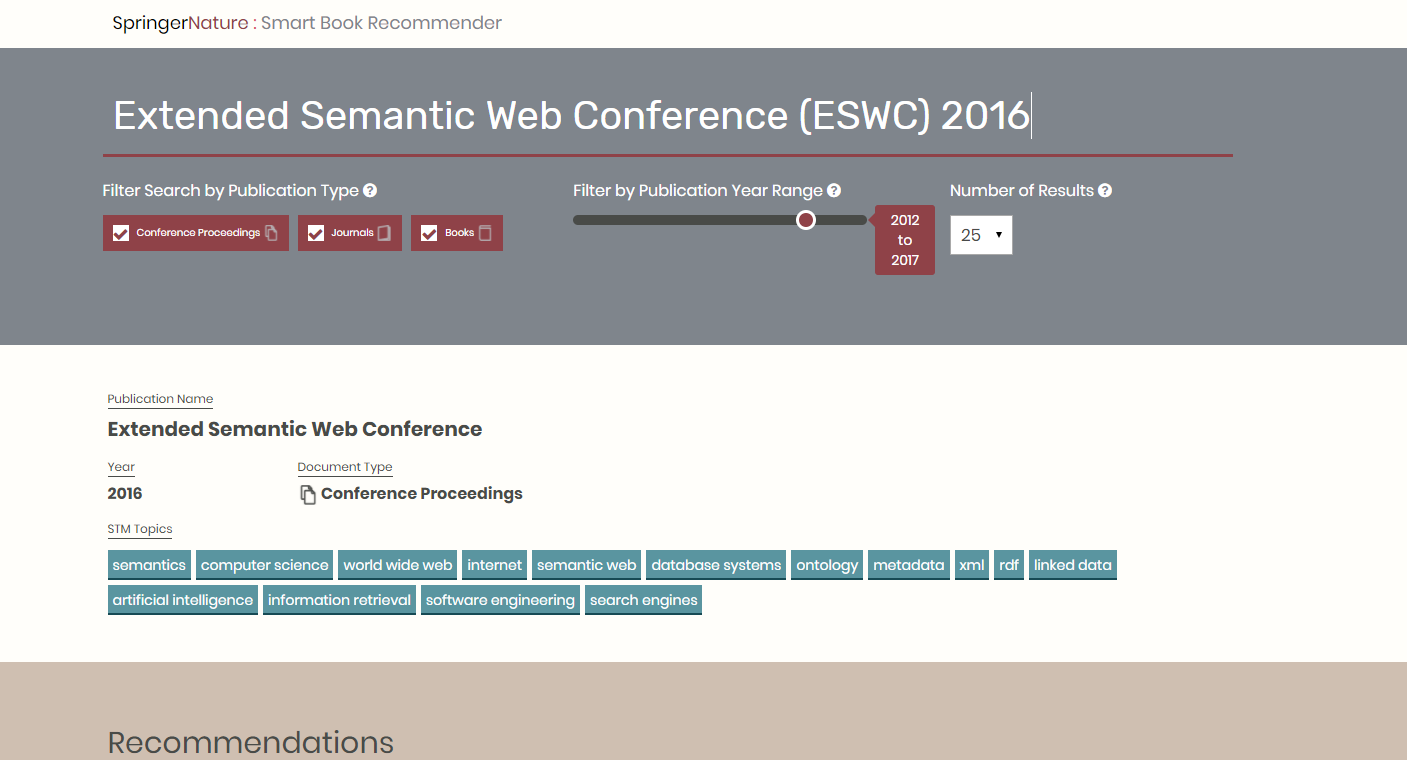
Smart Book Recommender
The Smart Book Recommender (SBR) is a semantic application designed to support the Springer Nature editorial team in promoting their publications at Computer Science venues. It takes as input the proceedings of a conference and suggests books, journals, and other conference proceedings that are likely to be relevant to the attendees of the conference in question. It […]

2100 AI: Reflections on the mechanisation of scientific discovery
“2100 AI: Reflections on the mechanisation of scientific discovery” is a paper submitted to the RE-CODING BLACK MIRROR Workshop co-located with the International Semantic Web Conference (ISWC) 2017, 21-25 October 2017, Vienna, Austria. Authors Andrea Mannocci, Angelo Salatino, Francesco Osborne and Enrico Motta Abstract The pace of nowadays research is hectic. Datasets and papers are […]
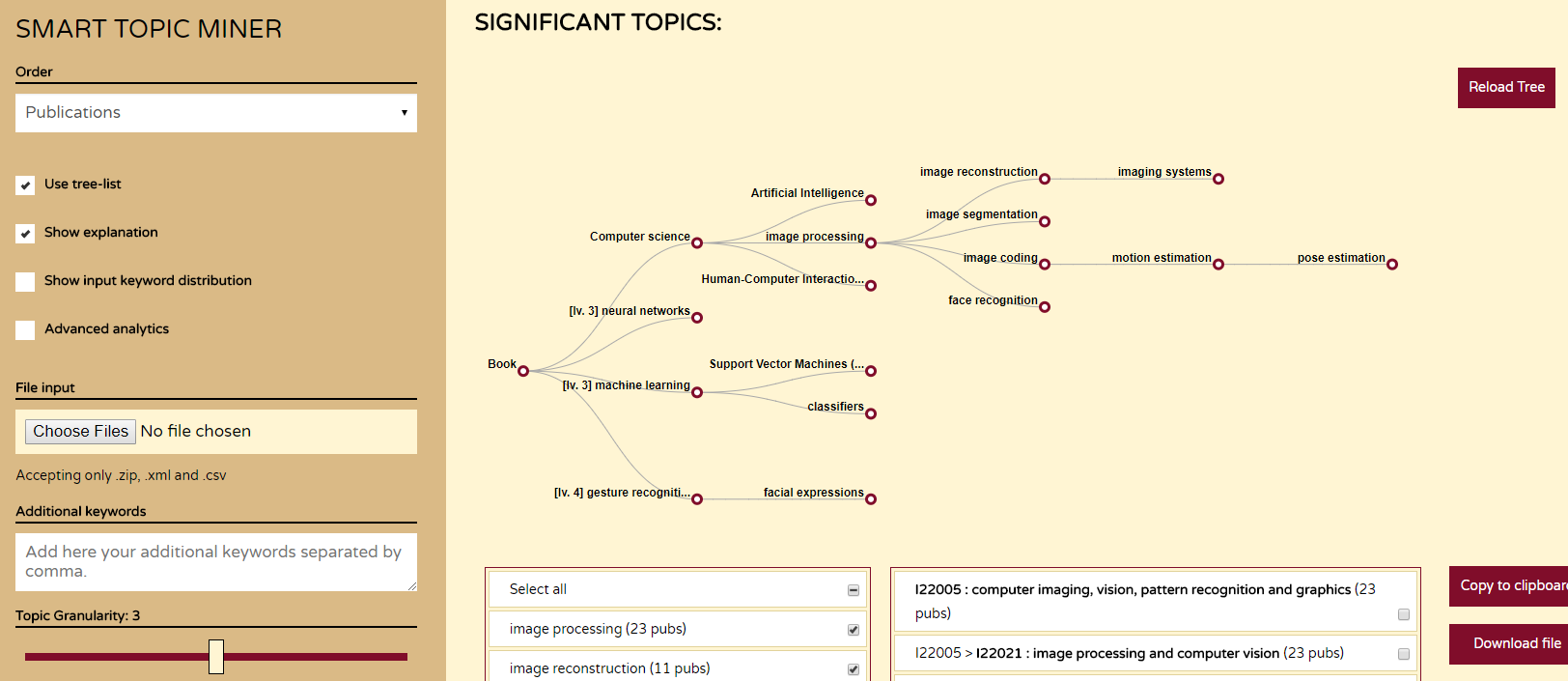
Supporting Springer Nature Editors by means of Semantic Technologies
“Supporting Springer Nature Editors by means of Semantic Technologies” is a research paper accepted to the Industry Track at the International Semantic Web Conference (ISWC) 2017 , 21-25 October 2017, Vienna, Austria. Authors Francesco Osborne, Angelo Salatino, Thiviyan Thanapalasingam, Aliaksandr Birukou and Enrico Motta Abstract The Open University and Springer Nature have been collaborating since 2015 […]
Smart Book Recommender: A Semantic Recommendation Engine for Editorial Products
“Smart Book Recommender: A Semantic Recommendation Engine for Editorial Products” is a poster paper that will be presented at the International Semantic Web Conference (ISWC) 2017, 21-25 October 2017, Vienna, Austria. Authors Francesco Osborne, Thiviyan Thanapalasingam, Angelo Salatino, Aliaksandr Birukou and Enrico Motta Abstract Academic publishers, such as Springer Nature, need to constantly make informed decisions […]

Book Review: Weapons of Math Destruction of Cathy O’Neil
Everyday activities are more and more shifting to a digital environment. Digital gadgets such as smartphones and werable devices are becoming inseparable part of our lives promising mostly convenience. New digital technologies have been mainly seen as empowering technologies for the users. FitBit, for example, is claimed to be a motivating device to lead a […]