
Abstract
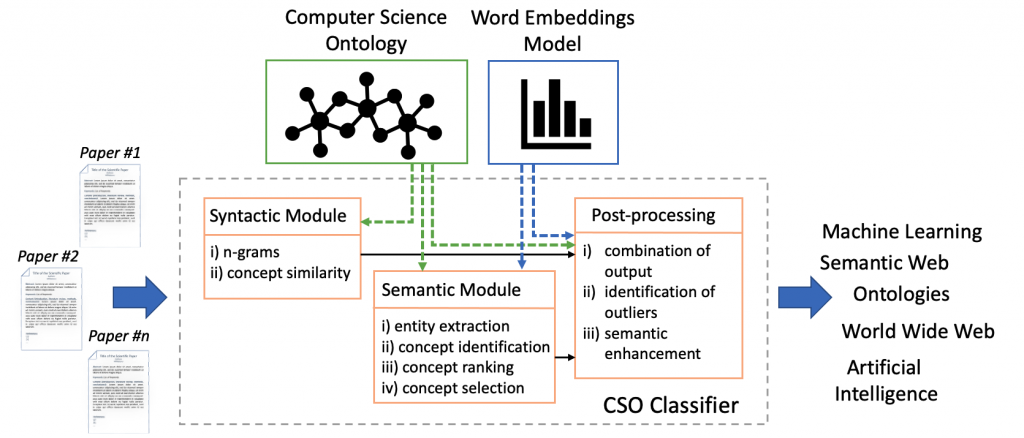
Classifying research papers according to their research topics is an important task to improve their retrievability, assist the creation of smart analytics, and support a variety of approaches for analysing and making sense of the research environment. In this repository, we present the CSO Classifier, a new unsupervised approach for automatically classifying research papers according to the Computer Science Ontology (CSO), a comprehensive ontology of research areas in the field of Computer Science. The CSO Classifier takes as input the metadata associated with a research paper (title, abstract, keywords) and returns a selection of research concepts drawn from the ontology. The approach was evaluated on a gold standard of manually annotated articles yielding a significant improvement over alternative methods.
v3.0
This release welcomes some improvements under the hood. In particular:
- we refactored the code, reorganising scripts into more elegant classes
- we added functionalities to automatically setup and update the classifier to the latest version of CSO
- we added the explanation feature, which returns chunks of text that allowed the classifier to infer a given topic
- the syntactic module takes now advantage of Spacy POS tagger (as previously done only by semantic module)
- the grammar for the chunk parser is now more robust:
{<JJ.*>*<HYPH>*<JJ.*>*<HYPH>*<NN.*>*<HYPH>*<NN.*>+}
In addition, in the post-processing module, we added the outlier detection component. This component improves the accuracy of the result set, by removing erroneous topics that were conceptually distant from the others. This component is enabled by default and can be disabled by setting delete_outliers = False when calling the CSO Classifier (see Parameters).
Please, be aware that having substantially restructured the code into classes, the way of running the classifier has changed too. Thus, if you are using a previous version of the classifier, we encourage you to update it (pip install -U cso-classifier) and modify your calls to the classifier, accordingly. Read our usage examples.
We would like to thank James Dunham @jamesdunham from CSET (Georgetown University) for suggesting to us how to improve the code.
Download from:
Full documentation available on GitHub readme file: https://github.com/angelosalatino/cso-classifier