Introduction
The SS-RR project (Sviluppo di un Sistema per la Rilevazione della Risonanza, english: Development of a System for Resonance Detection) aims to develop methodologies exploiting current technologies in order to provide innovative services. In particular, the detection of harmony levels between one or more people in relation to external stimuli. For example, the measure of satisfaction gradient of an interlocutor, happiness gradient of an interviewed person and so on.
In a quite similar scenario, using smartphones, iPhone and other last generation devices it is possible to exploit their sensors to acquire data in order to detect the emotional status. This kind of data are then combined to build a psychological model in order to bind physical-emotional parameters to people’s mood.
The aim of this project was to develop a software application to be installed on equipments and then used during staff selection. A typical scenario is depicted in Figure 1. The software first acquires sounds, facial expressions and also movement of the candidate body and it processes data in order to assess resonance or dissonance evaluating also the synergy between the two subjects.
Partners
- AMT Services SRL
- Laboratorio di Informatica Industriale – Dipartimento di Ingegneria Elettrica e dell’Informazione, Politecnico di Bari.
Official Website of the Project
http://www.vitoantoniobevilacqua.it/lab/?p=79
Methods
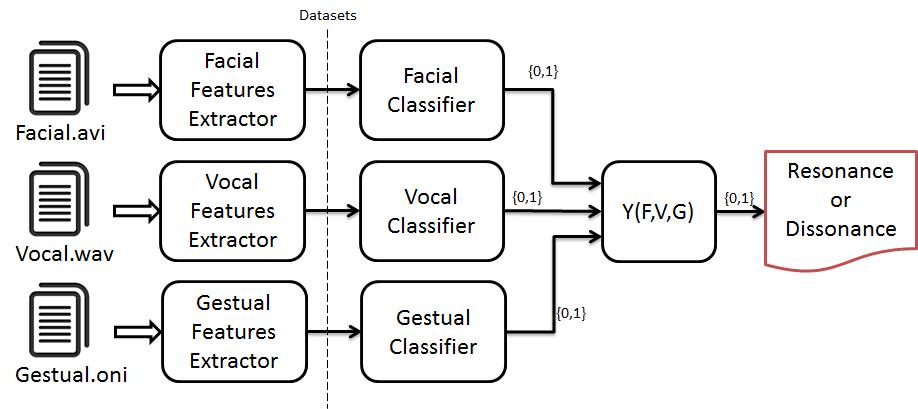
The entire application is based on the design, the development and also the integration of three independent modules able to work independently on their own domain: facial, vocal and gestural.
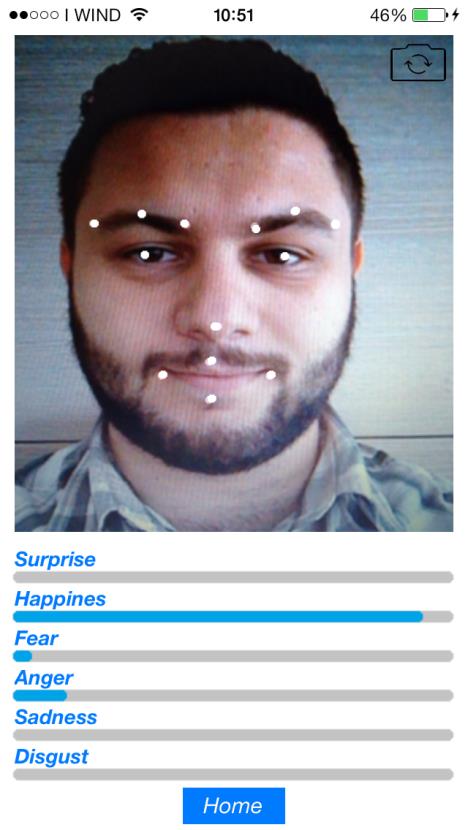
In particular, from a facial stream (acquired from HD webcam and then stored in avi file) action units are extracted (AUs). Action units are minimal facial actions which combined produce facial expressions, i.e. lips movements, wrinkle movements and so on (as it is shown in Figure 2). Instead, in Figure 3 the workflow employed to extract the AUs is showed.
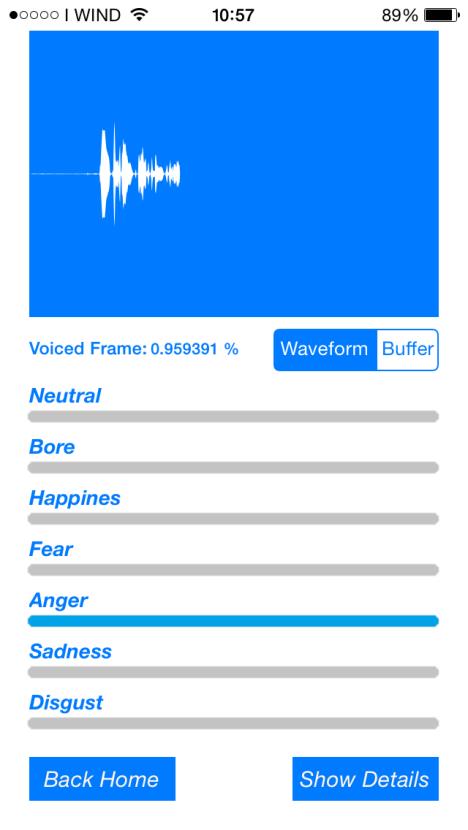

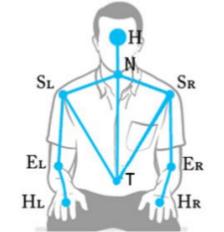
In vocal domain, prosodic and spectral features are extracted such as Pitch, MFCC and harmonicity. All these features have an high variability and then some statistical indexes have been considered as average value, standard deviation, minimum and maximum values and range. For gestural domain, a system able to identify 13 different human action has been designed. Processing the depth map, some features corresponding to joints and also distances between joints have been extracted, i.e. left shoulder, hands, elbows and so on, as showed in Figure 4.
In Figure 5, the system architecture is shown, depicting how the different components merge to define the resonance or dissonance status.
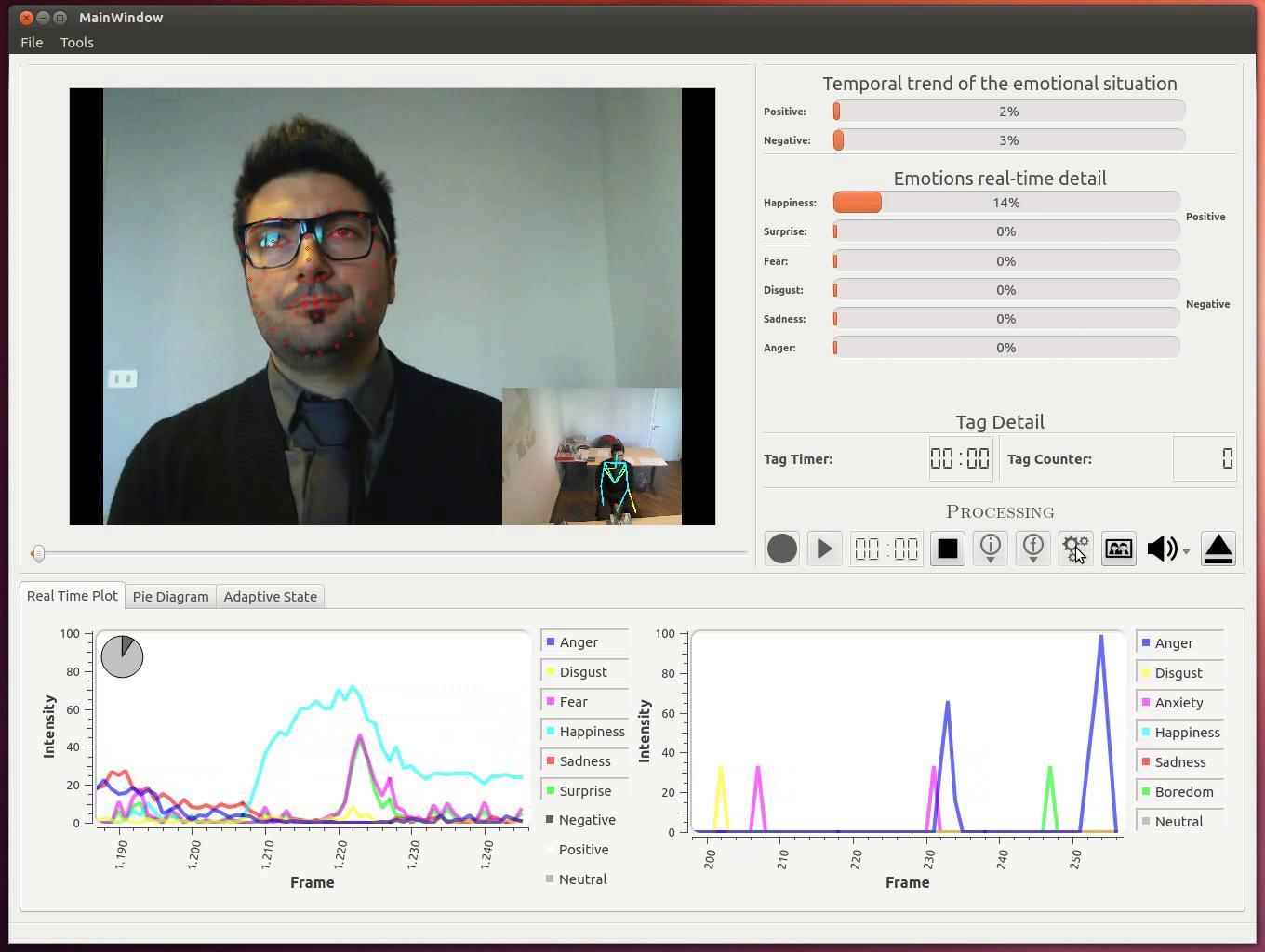
In Figure 6 the graphical interface of the final application is showed where in the top left corner facial a processing view is displayed (with red marked attached to the face) and gestural processing (skeleton). In the top right corner there are the real-time emotions evaluation with some plots in the bottom.
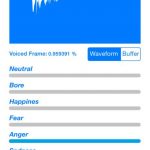
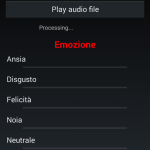
Mobile iOS/Android
Along with the desktop application also mobile application, for iOS and Android environments, have been developed. These application aim to recognize emotions only from vocal e facial streams.


References
- Vitoantonio Bevilacqua, Donato Barone, Francesco Cipriani, Gaetano D’Onghia, Giuseppe Mastrandrea, Giuseppe Mastronardi, Marco Suma, Dario D’Ambruoso: “A new tool for gestural action recognition to support decisions in emotional framework”, IEEE INISTA 2014, pp 184-191, (June 2014). [DOI]
- Vitoantonio Bevilacqua, Angelo Antonio Salatino, Carlo Di Leo, Dario D’Ambruoso, Marco Suma, Donato Barone, Giacomo Tattoli, Domenico Campagna, Fabio Stroppa, Michele Pantaleo: Evaluation of Resonance in Staff Selection through Multimedia Contents. ICIC (2) 2014: 185-198 [DOI]
- Vitoantonio Bevilacqua, Pietro Guccione, Luigi Mascolo, Pasquale Pio Pazienza, Angelo Antonio Salatino, Michele Pantaleo: First Progresses in Evaluation of Resonance in Staff Selection through Speech Emotion Recognition. ICIC (2) 2013: 658-671 [DOI]
- Vitoantonio Bevilacqua, Marco Suma, Dario D’Ambruoso, Giovanni Mandolino, Michele Caccia, Simone Tucci, Emanuela De Tommaso, Giuseppe Mastronardi: A Supervised Approach to Support the Analysis and the Classification of Non Verbal Humans Communications. ICIC (1) 2011: 426-431 [DOI]
- Claudio Loconsole, Domenico Chiaradia, Vitoantonio Bevilacqua, Antonio Frisoli: Real-Time Emotion Recognition: An Improved Hybrid Approach for Classification Performance. ICIC (1) 2014: 320-331 [DOI]