
Academia and industry are constantly engaged in a joint effort for producing scientific knowledge that will shape the society of the future. Analysing the knowledge flow between them and understanding how they influence each other is a critical task for researchers, governments, funding bodies, investors, and companies. However, current corpora are unfit to support large-scale analysis of the knowledge flow between academia and industry since they lack of a good characterization of research topics and industrial sectors. In this short paper, we introduce the Academia/Industry DynAmics (AIDA) Knowledge Graph, which characterizes 14M papers and 8M patents according to the research topics drawn from the Computer Science Ontology. 4M papers and 5M patents are also classified according to the type of the author’s affiliations (academy, industry, or collaborative) and 66 industrial sectors (e.g., automotive, financial, energy, electronics) obtained from DBpedia. AIDA was generated by an automatic pipeline that integrates several knowledge graphs and bibliographic corpora, including Microsoft Academic Graph, Dimensions, English DBpedia, the Computer Science Ontology, and the Global Research Identifier Database.
Blog

Angelo and Tina on the PhD journey
Have you thought of doing a PhD, you are currently doing or you have finished? I have. It’s painful and rewarding. In this episode, I talk with Dr Tina Papathoma, a post-doctoral researcher in Technology Enhanced Learning, about the PhD journey and the impact it has on us. We talk about the PhD process, submission and viva in an honest discussion of a 4 years journey.

Academia/Industry DynAmics (AIDA) Knowledge Graph
Academia and industry share a complex, multifaceted, and symbiotic relationship. Analysing the knowledge flow between them, understanding which directions have the biggest potential, and discovering the best strategies to harmonise their efforts is a critical task for several stakeholders. While research publications and patents are an ideal media to analyse this space, current datasets of […]

Just Chilling with Angelo Salatino
I like to tell stories. I like to explore people’s story. I feel there is always something to learn from other people’s experiences.
In will use this space to share with you in the most honest and genuine way all stories worth listening.
I hope you would like it. Stay tuned.

I launched an online course on Instagram, here is my lesson learned
THIS IS A DRAFT – WORK IN PROGRESS During the COVID-19 outbreak many people relied more and more on web technologies like such as video calls and social networks, to fulfil their social needs. I decided to design and release an online course on Instagram so that users while consuming content could be engaged in […]
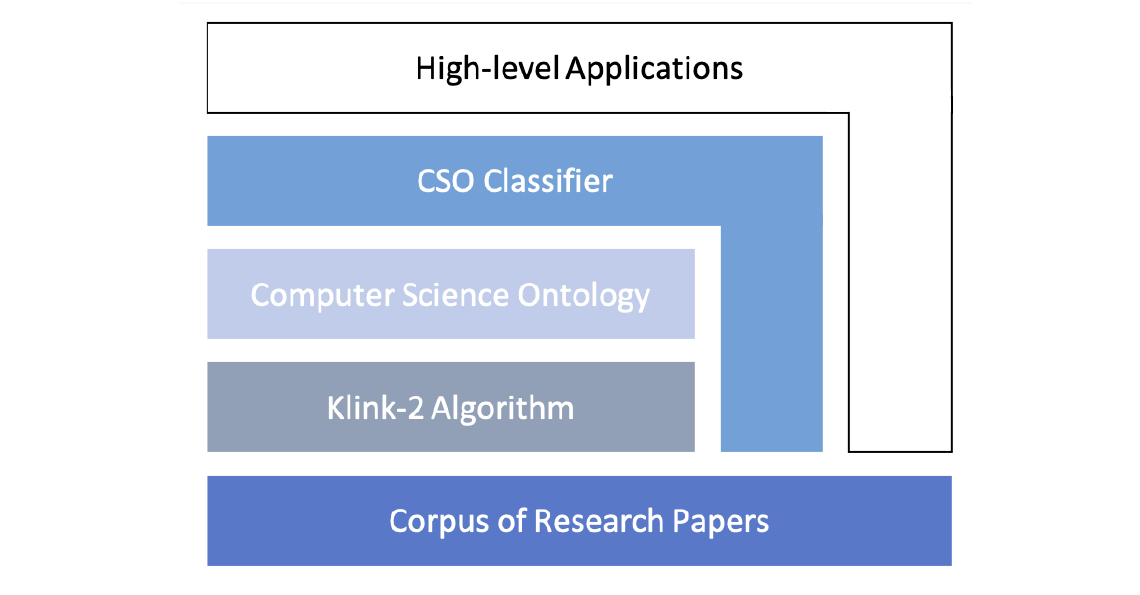
Ontology Extraction and Usage in the Scholarly Knowledge Domain
Ontologies of research areas have been proven to be useful in many application for analysing and making sense of scholarly data. In this chapter, we present the Computer Science Ontology (CSO), which is the largest ontology of research areas in the field of Computer Science, and discuss a number of applications that build on CSO, to support high-level tasks, such as topic classification, metadata extraction, and recommendation of books.
1st Workshop on Scientific Knowledge Graphs (SKG2020)
In the last decade, we experienced an urgent need for a flexible, context-sensitive, fine-grained, and machine-actionable representation of scholarly knowledge and corresponding infrastructures for knowledge curation, publishing and processing. Such technical infrastructures are becoming increasingly popular in representing scholarly knowledge as structured, interlinked, and semantically rich Scholarly Knowledge Graphs (SKG).
The 1st Workshop on Scientific Knowledge Graphs (SKG2020) aims at bringing together researchers and practitioners from different fields (including, but not limited to, Digital Libraries, Information Extraction, Machine Learning, Semantic Web, Knowledge Engineering, Natural Language Processing, Scholarly Communication, and Bibliometrics) in order to explore innovative solutions and ideas for the production and consumption of Scientific Knowledge Graphs (SKGs).

Computing Automorphic Numbers
In our lab, we like to tease each other with fancy riddles. In our kitchen, we have a large wooden box, filled with some chocolates and locked by a 4-digits lock. Those who crave for some sugar will just need to solve the riddle and unlock the box.
The last few riddles involved a particular family of numbers which are called automorphic, and the complexity of such riddles was increasing with the size of those numbers in terms of the number of digits. For instance, in the last riddle, we were asked to compute a number with 44444 digits, requiring an enormous computational power.
In this post, I will show how I developed the algorithm that allowed me to solve the riddle.

1st Smart City and Robotic Challenge (SCiRoC 2019)
Last week — 18th to 21st September 2019 — the first International Competition on Smart Cities and Robotics took place in Milton Keynes (UK). Different teams from Spain, UK, Germany, France, Portugal and others took part in this competition. As the name suggests, SCiRoC aims at bringing robots in the context of smart cities. Indeed, their primary objective was to interact both with smart cities infrastructures, such as the MK Data Hub, and citizens.

How to use the CSO Classifier in other domains
Being able to characterise research papers according to their topics enables a multitude of high-level applications such as i) categorise proceedings in digital libraries, ii) semantically enhance the metadata of scientific publications, iii) generate recommendations, iv) produce smart analytics, v) detect research trends, and others.
In our recent work, we designed and developed an unsupervised approach to automatically classify research papers according to an ontology of research areas in the field of Computer Science. This approach uses well-known technologies from the field of Natural Language Processing which makes it easily generalisable. In this article, we will show how we can customise the CSO Classifier and apply it to other fields of Science.