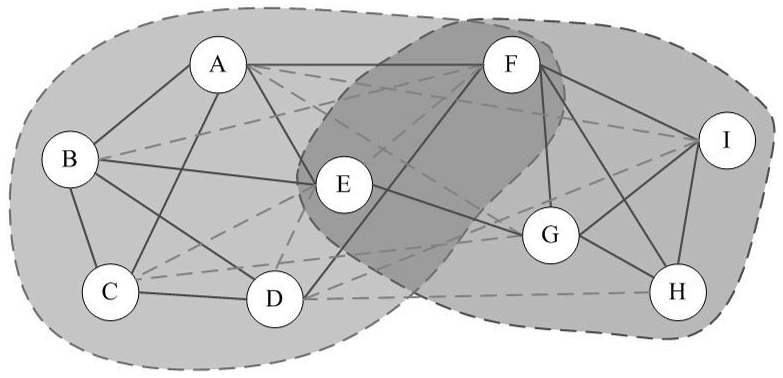
Clique Percolation Method (CPM) is an algorithm for finding overlapping communities within networks, introduced by Palla et al. (2005, see references). This implementation in Python, firstly detects communities of size k, then creates a clique graph. Each community will be represented by each connected component in the clique graph. Algorithm The algorithm performs the following […]
Blog

ISWC2020 – BEST DEMO OF THE DAY AWARD
The Smart Topic Miner, which is an innovative state-of-the-art AI application for automating editorial processes at Springer Nature and improving access to scientific knowledge, has been shortlisted for the “Most Innovative use of AI” DataIQ 2020 Awards. Smart Topic Miner analyses scientific publications in Computer Science and classifies them with very high accuracy in terms […]

Applying Machine Learning Techniques to Big Data in the Scholarly Domain
Ontologies of research areas have been proven to be useful in many application for analysing and making sense of scholarly data. In this lecture, I will present how we produced the Computer Science Ontology (CSO), which is the largest ontology of research areas in the field of Computer Science, and discuss a number of applications that build on CSO, to support high-level tasks, such as topic classification, research trends forecasting, metadata extraction, and recommendation of books.

Finalists at DataIQ 2020 Awards
The Smart Topic Miner, which is an innovative state-of-the-art AI application for automating editorial processes at Springer Nature and improving access to scientific knowledge, has been shortlisted for the “Most Innovative use of AI” DataIQ 2020 Awards. Smart Topic Miner analyses scientific publications in Computer Science and classifies them with very high accuracy in terms […]

The AIDA Dashboard: Analysing Conferences with Semantic Technologies
“The AIDA Dashboard: Analysing Conferences with Semantic Technologies” is a demo paper submitted to the Posters and Demos tracks of the 19th International Semantic Web Conference. Simone Angioni1, Francesco Osborne2, Angelo A. Salatino2, Diego Reforgiato Recupero1, Enrico Motta2 1 University of Cagliari, Via Università 40, 09124 Cagliari 2 Knowledge Media Institute, The Open University, […]
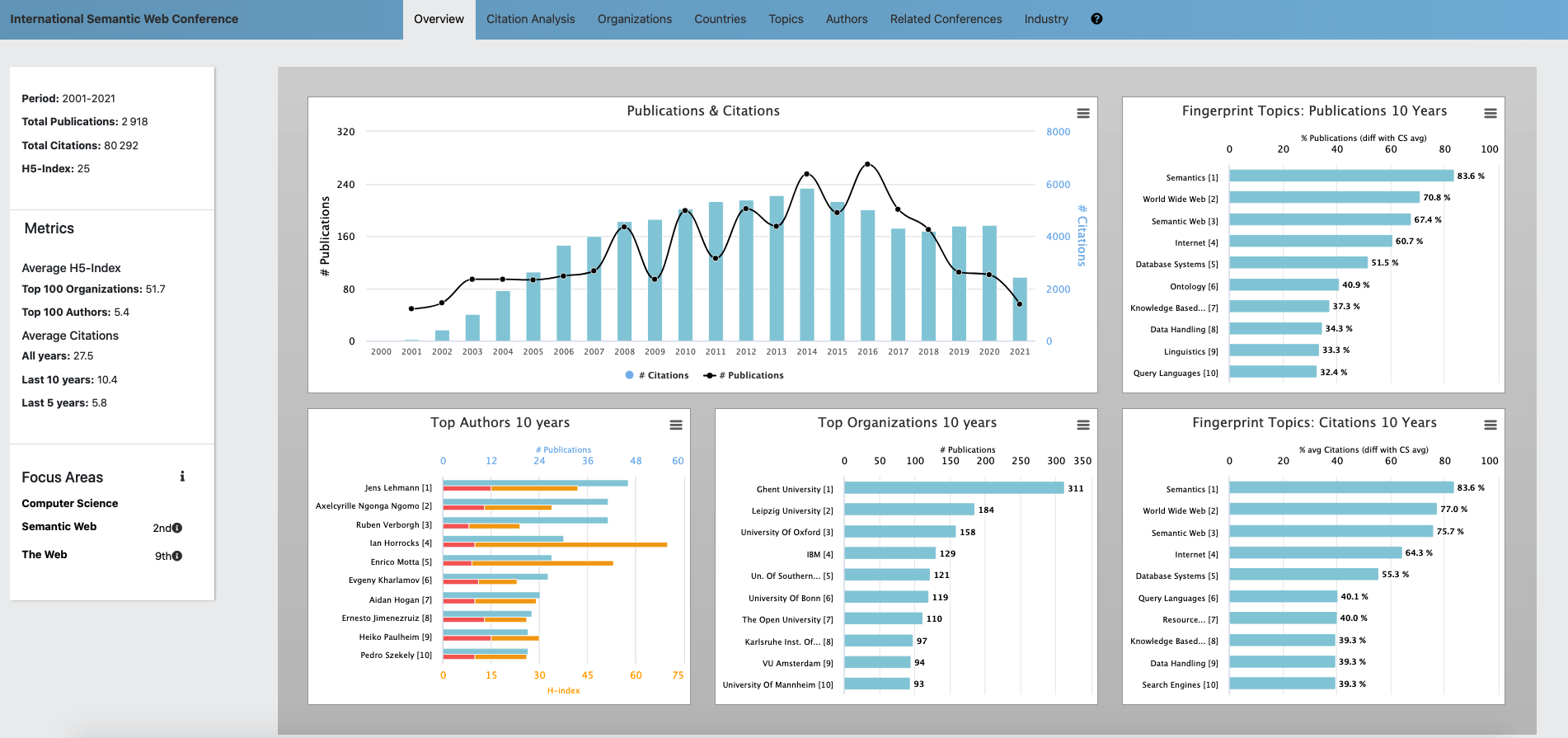
AIDA Dashboard
The AIDA Dashboard is a web application that allows users to visualize several kind of analytics about a specific conference (see Figure 1). The backend is developed in Python, while the frontend is in HTML5 and Javascript. The AIDA Dashboard builds on the Academia/Industry DynAmics knowledge graph (AIDA), a large knowledge base describing 14M articles […]

Databases and Information Systems in the AI Era: Contributions from ADBIS, TPDL and EDA 2020 Workshops and Doctoral Consortium
“Databases and Information Systems in the AI Era: Contributions from ADBIS, TPDL and EDA 2020 Workshops and Doctoral Consortium” is the introductory chapter for the ADBIS , TPDL and EDA 2020 Common Workshops and Doctoral Consortium proceedings as satellite events of the 2020 International Conference on Theory and Practice of Digital Libraries (TPDL2020). Ladjel Bellatreche, […]
‘PhD Survival Guide’, Angelo and Akshika, The Open University
This is a little project that my friend Akshika and I brought forward with the support of The Open University. In this video, we talk about the things we wish we had known before starting our PhD journey. Are you a PhD student or are you planning to start soon? Give it a look.

ResearchFlow: Understanding the Knowledge Flow between Academia and Industry
“ResearchFlow: Understanding the Knowledge Flow between Academia and Industry” is a conference paper submitted to Knowledge Engineering and Knowledge Management – 22nd International Conference, EKAW 2020. Angelo Salatino, Francesco Osborne, Enrico Motta Abstract Understanding, monitoring, and predicting the flow of knowledge between academia and industry is of critical importance for a variety of stakeholders, including governments, funding […]

Angelo and Edu Frias on the PhD Defence
Going through the final stages of your PhD? No worries! We’ve got you covered. In this episode, I invited Dr Eduardo Frias-Anaya, who defended his thesis two weeks ago, at the Open University in the UK, to talk about the final stages of a PhD. We talk about writing up a dissertation, preparation to the […]