
“New trends in scientific knowledge graphs and research impact assessment” is the introductory chapter of the Special Issue on “Scientific Knowledge Graphs and Research Impact Assessment” at Quantitative Science Studies (QSS by MIT Press). Paolo Manghi1, Andrea Mannocci1, Francesco Osborne2, Dimitris Sacharidis3, Angelo Salatino2, Thanasis Vergoulis4 1 CNR-ISTI – National Research Council, Institute of Information Science […]
Blog

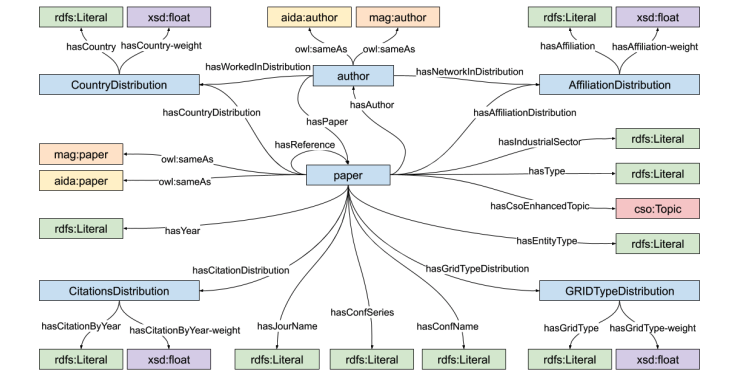
AIDA: a Knowledge Graph about Research Dynamics in Academia and Industry
“AIDA: a Knowledge Graph about Research Dynamics in Academia and Industry” is a research paper published at the Special Issue on “Scientific Knowledge Graphs and Research Impact Assessment” at Quantitative Science Studies (QSS by MIT Press). Simone Angioni1, Angelo Antonio Salatino2, Francesco Osborne2, Diego Reforgiato Recupero1, Enrico Motta2 1 Department of Mathematics and Computer Science, University […]

Assessing Scientific Conferences through Knowledge Graphs
“Assessing Scientific Conferences through Knowledge Graphs” is a paper published at the Industry Track of the 2021 International Semantic Web Conference. Simone Angioni1, Angelo Antonio Salatino2, Francesco Osborne2, Aliaksandr Birukou3, Diego Reforgiato Recupero1, Enrico Motta2 1 Department of Mathematics and Computer Science, University of Cagliari (Italy) 2 Knowledge Media Institute, The Open University, Milton Keynes (UK) […]
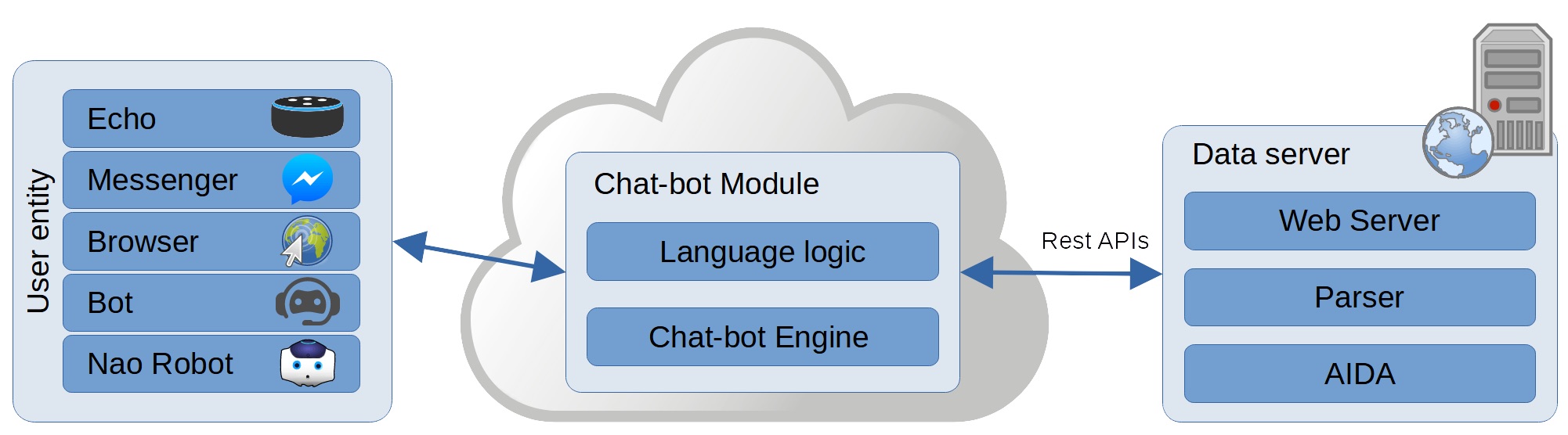
AIDA-Bot: A Conversational Agent to Explore Scholarly Knowledge Graphs
“AIDA-Bot: A Conversational Agent to ExploreScholarly Knowledge Graphs” is a demo paper accepted for presentation at the International Semantic Web Conference (ISWC 2021) poster and demo session. Antonello Meloni1, Simone Angioni1, Angelo Antonio Salatino2, Francesco Osborne2, Diego Reforgiato Recupero1, Enrico Motta2 1 Department of Mathematics and Computer Science, University of Cagliari (Italy) 2 Knowledge Media […]
Link Prediction of Weighted Triples for Knowledge Graph Completion Within the Scholarly Domain
“Link Prediction of Weighted Triples for Knowledge Graph Completion Within the Scholarly Domain” is a journal paper accepted at IEEE Access Mojtaba Nayyeri1,2, Gökce Müge Cil1, Sahar Vahdati2, Francesco Osborne3, Andrey Kravchenko4, Simone Angioni5, Angelo Salatino3, Diego Reforgiato Recupero5, Enrico Motta3, Jens Lehmann1,6 1 SDA Research Group, University of Bonn, 53115 Bonn, Germany 2 […]

CSO Classifier 3.0
Abstract Classifying research papers according to their research topics is an important task to improve their retrievability, assist the creation of smart analytics, and support a variety of approaches for analysing and making sense of the research environment. In this repository, we present the CSO Classifier, a new unsupervised approach for automatically classifying research papers […]

Detection, Analysis, and Prediction of Research Topics with Scientific Knowledge Graphs
“Detection, Analysis, and Prediction of Research Topics with Scientific Knowledge Graphs” is a book chapter of “Predicting the Dynamics of Research Impact” edited by Springer. Angelo A. Salatino1, Andrea Mannocci2, and Francesco Osborne1 1Knowledge Media Institute – The Open University, Milton Keynes, United Kingdom 2Istituto di Scienza e Tecnologie dell’Informazione “A. Faedo”, Italian National Research […]

CSO Classifier 3.0: A Scalable Unsupervised Method for Classifying Documents in Terms of Research Topics
“CSO Classifier 3.0: A Scalable Unsupervised Method for Classifying Documents in Terms of Research Topics” is a journal paper accepted at the Special Issue of “TPDL 2019 & 2020” at Scientometrics. Angelo Salatino, Francesco Osborne, Enrico Motta Abstract Classifying scientific articles, patents, and other documents according to the relevant research topics is an important task, […]

Trans4E: Link Prediction on Scholarly Knowledge Graphs
“Trans4E: Link Prediction on Scholarly Knowledge Graphs” is a journal paper submitted to the Special Issue on “Knowledge Graph Representation & Reasoning” at the Neurocomputing Journal Mojtaba Nayyeria, Gokce Muge Cila, Sahar Vahdatib, Francesco Osborned, Mahfuzur Rahmana,Simone Angionie, Angelo Salatinod, Diego Reforgiato Recuperoe, Nadezhda Vassilyevaa, Enrico Mottad and Jens Lehmanna,c aSDA Research Group, University […]

Scientific Knowledge Graphs: an Overview
On 12th May 2021, I have been invited by Dimitris Sacharidis to give a lecture to the master course is INFO-H509 “XML and Web Technologies” at the Université Libre de Bruxelles. Abstract In the last decade, several Scientific Knowledge Graphs (SKG) were released, representing scientific knowledge in a structured, interlinked, and semantically rich manner. But, what […]