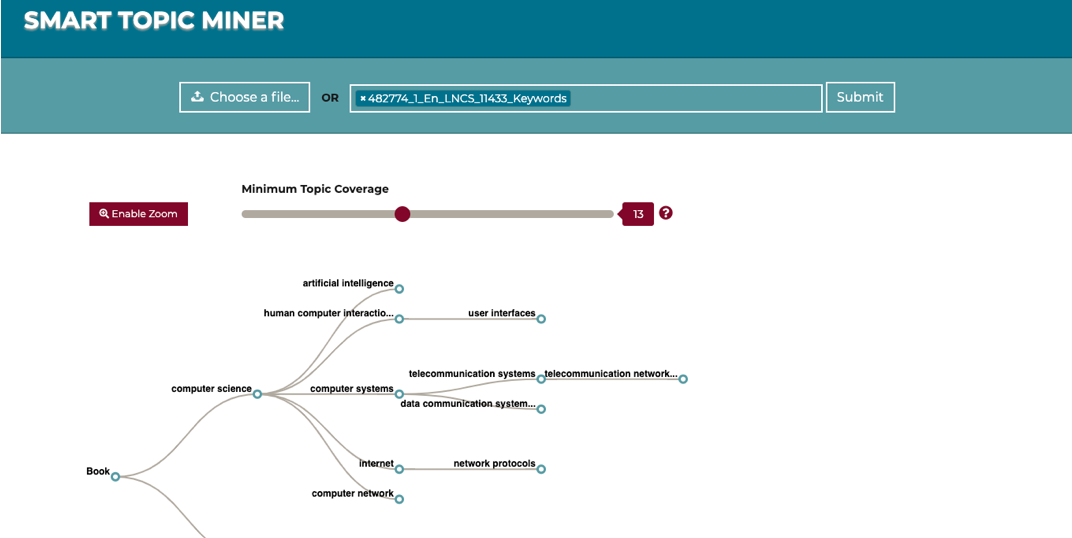
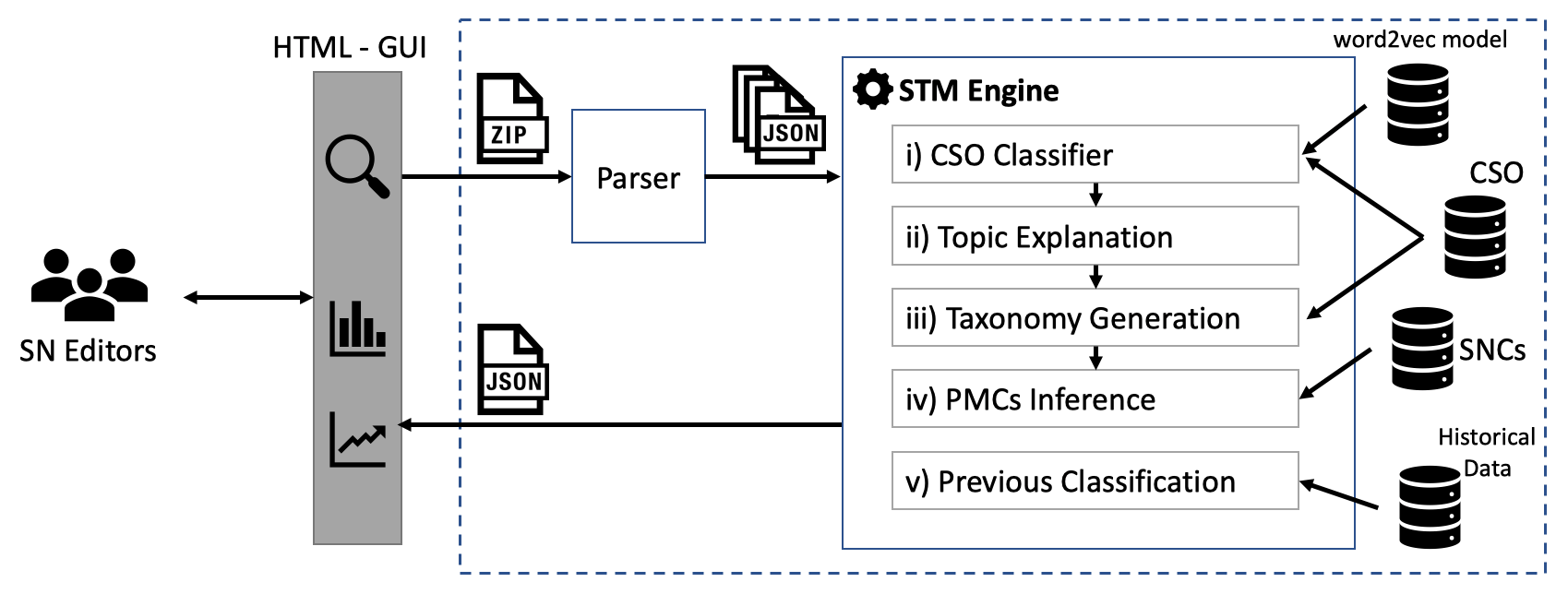
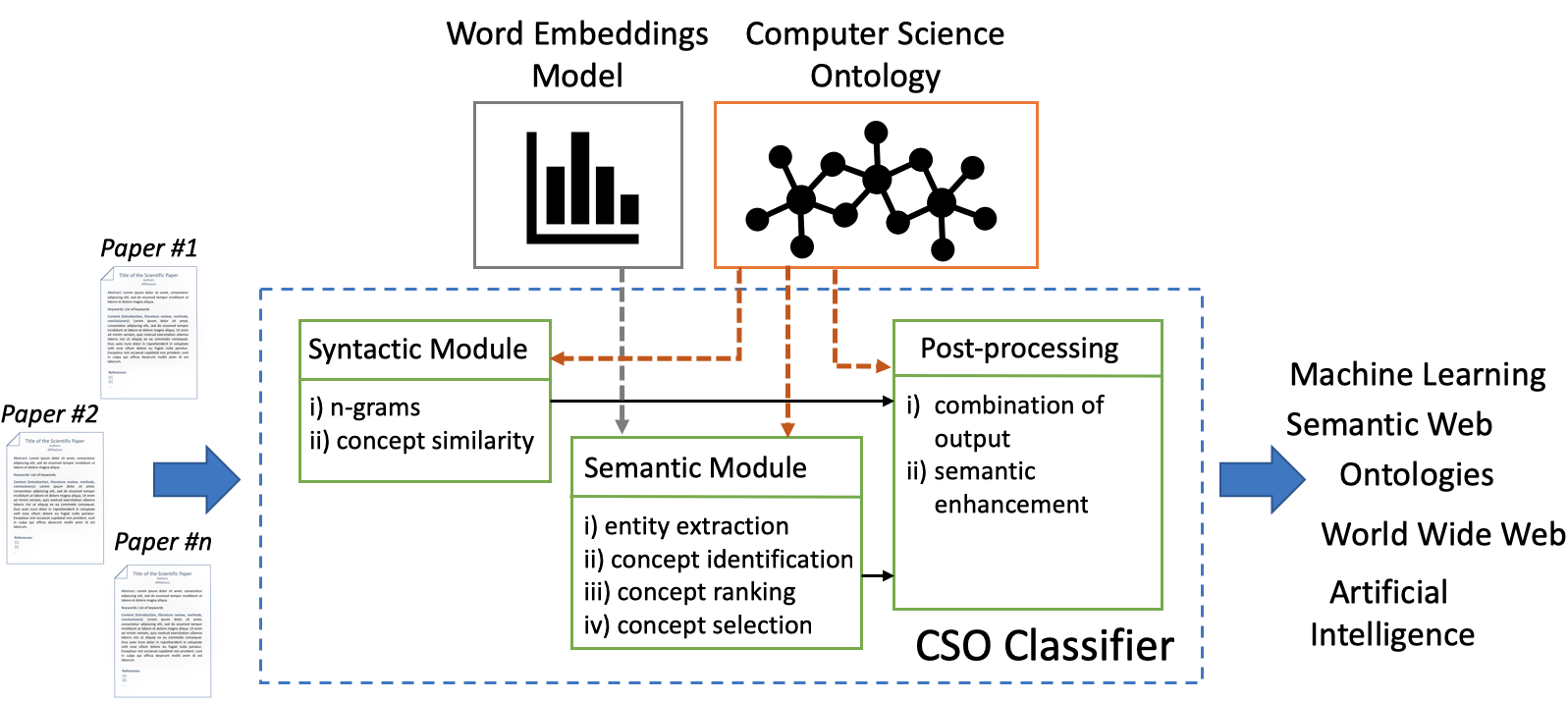
Being able to characterise research papers according to their topics enables a multitude of high-level applications such as i) categorise proceedings in digital libraries, ii) semantically enhance the metadata of scientific publications, iii) generate recommendations, iv) produce smart analytics, v) detect research trends, and others.
In our recent work, we designed and developed an unsupervised approach to automatically classify research papers according to an ontology of research areas in the field of Computer Science. This approach uses well-known technologies from the field of Natural Language Processing which makes it easily generalisable. In this article, we will show how we can customise the CSO Classifier and apply it to other fields of Science.