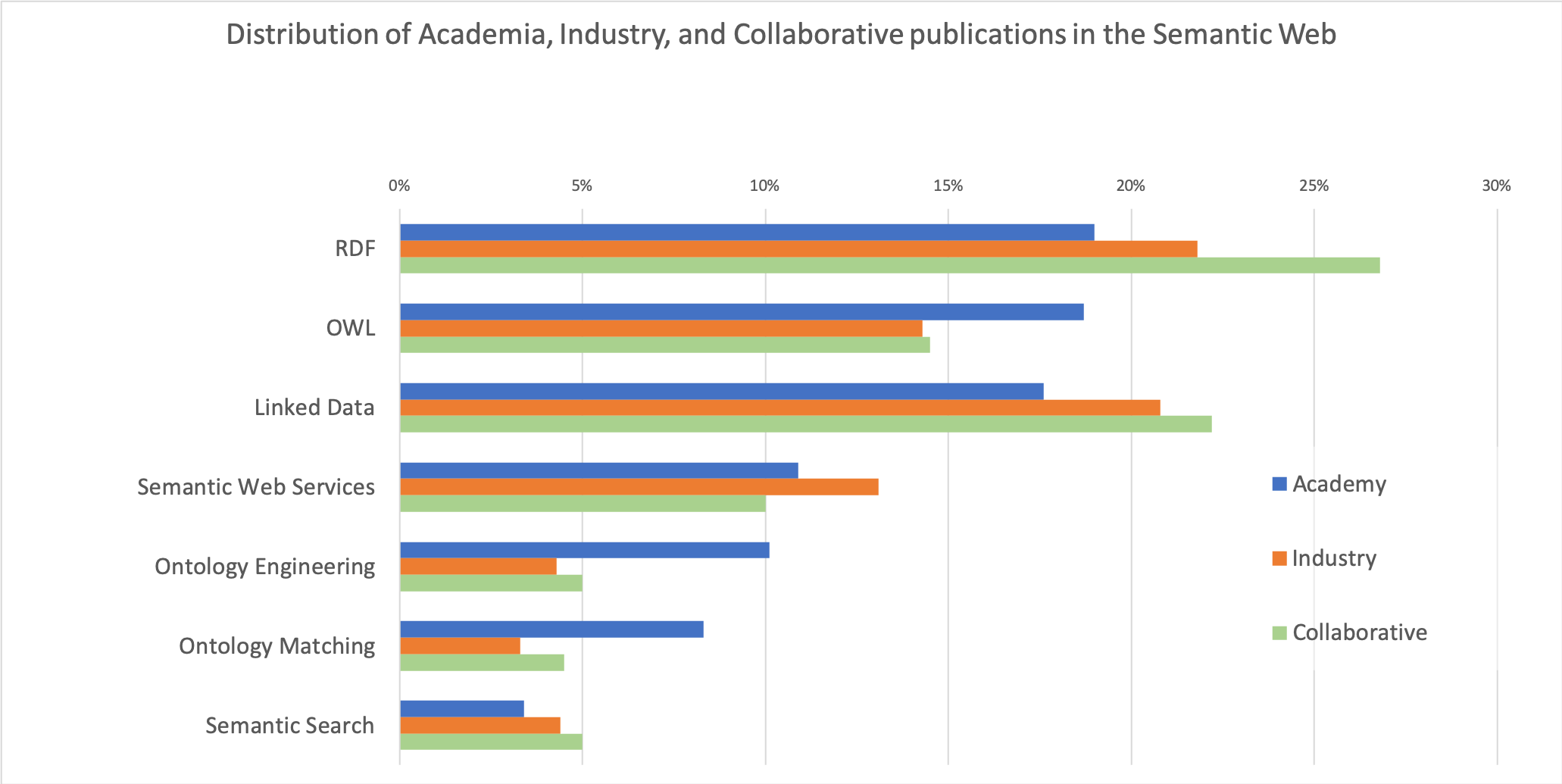
Analysing the relationship between academia and industry allows us to understand how the knowledge produced by the universities is being adopted and enriched by the industrial sector, and ultimately affects society through the release of relevant products and services. In this paper, we present a preliminary approach to assess and compare the research outputs of academia and industry. This solution integrates data from several knowledge graphs describing scientific articles (Microsoft Academics Graph), research topics (Computer Science Ontology), organizations (Global Research Identifier Database), and types of industry (DBpedia). We focus on the Semantic Web as exemplary field and report several insights regarding the different behaviours of academia and industry, and the types of industries most active in this field.
Tag: Scholarly Data
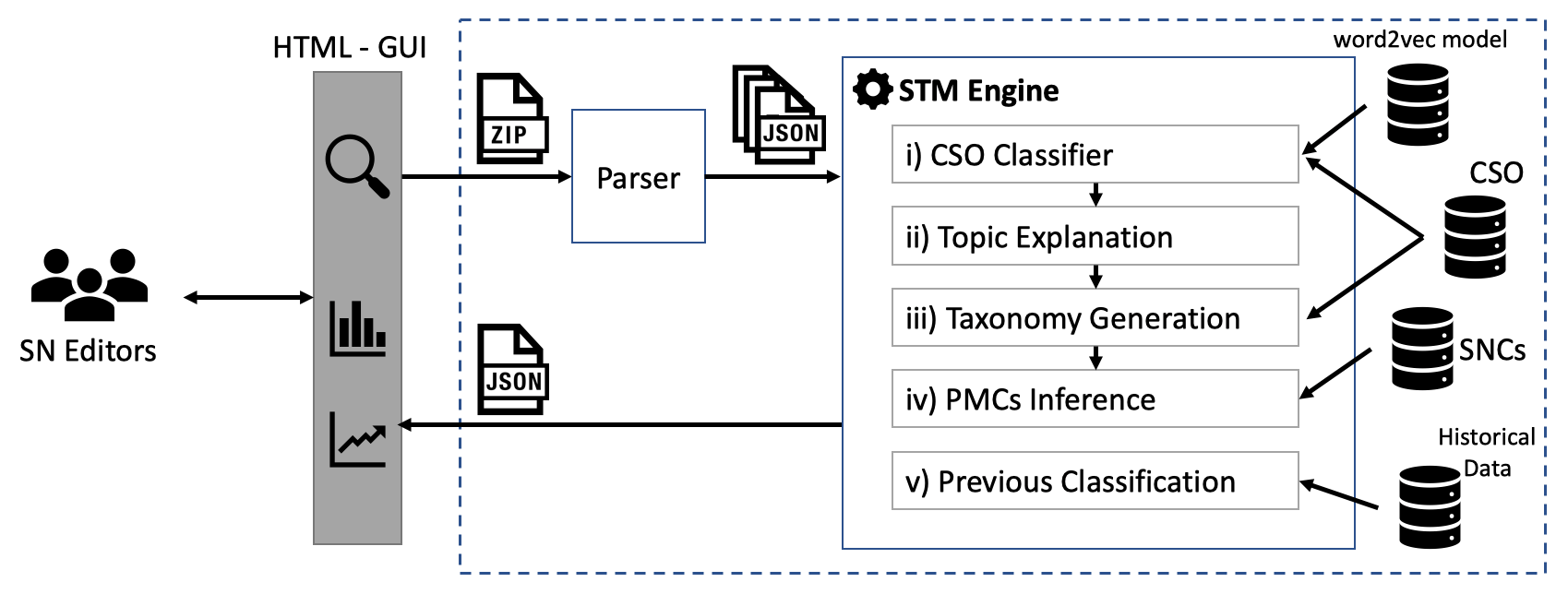
Improving Editorial Workflow and Metadata Quality at Springer Nature
Identifying the research topics that best describe the scope of a scientific publication is a crucial task for editors, in particular because the quality of these annotations determine how effectively users are able to discover the right content in online libraries. For this reason, Springer Nature, the world’s largest academic book publisher, has traditionally entrusted this task to their most expert editors. These editors manually analyse all new books, possibly including hundreds of chapters, and produce a list of the most relevant topics. Hence, this process has traditionally been very expensive, time-consuming, and confined to a few senior editors. For these reasons, back in 2016 we developed Smart Topic Miner (STM), an ontology-driven application that assists the Springer Nature editorial team in annotating the volumes of all books covering conference proceedings in Computer Science. Since then STM has been regularly used by editors in Germany, China, Brazil, India, and Japan, for a total of about 800 volumes per year. Over the past three years the initial prototype has iteratively evolved in response to feedback from the users and evolving requirements.

The CSO Classifier: Ontology-Driven Detection of Research Topics in Scholarly Articles
Classifying research papers according to their research topics is an important task to improve their retrievability, assist the creation of smart analytics, and support a variety of approaches for analysing and making sense of the research environment. In this paper, we present the CSO Classifier, a new unsupervised approach for automatically classifying research papers according to the Computer Science Ontology (CSO), a comprehensive ontology of research areas in the field of Computer Science. The CSO Classifier takes as input the metadata associated with a research paper (title, abstract, keywords) and returns a selection of research concepts drawn from the ontology. The approach was evaluated on a gold standard of manually annotated articles yielding a significant improvement over alternative methods.
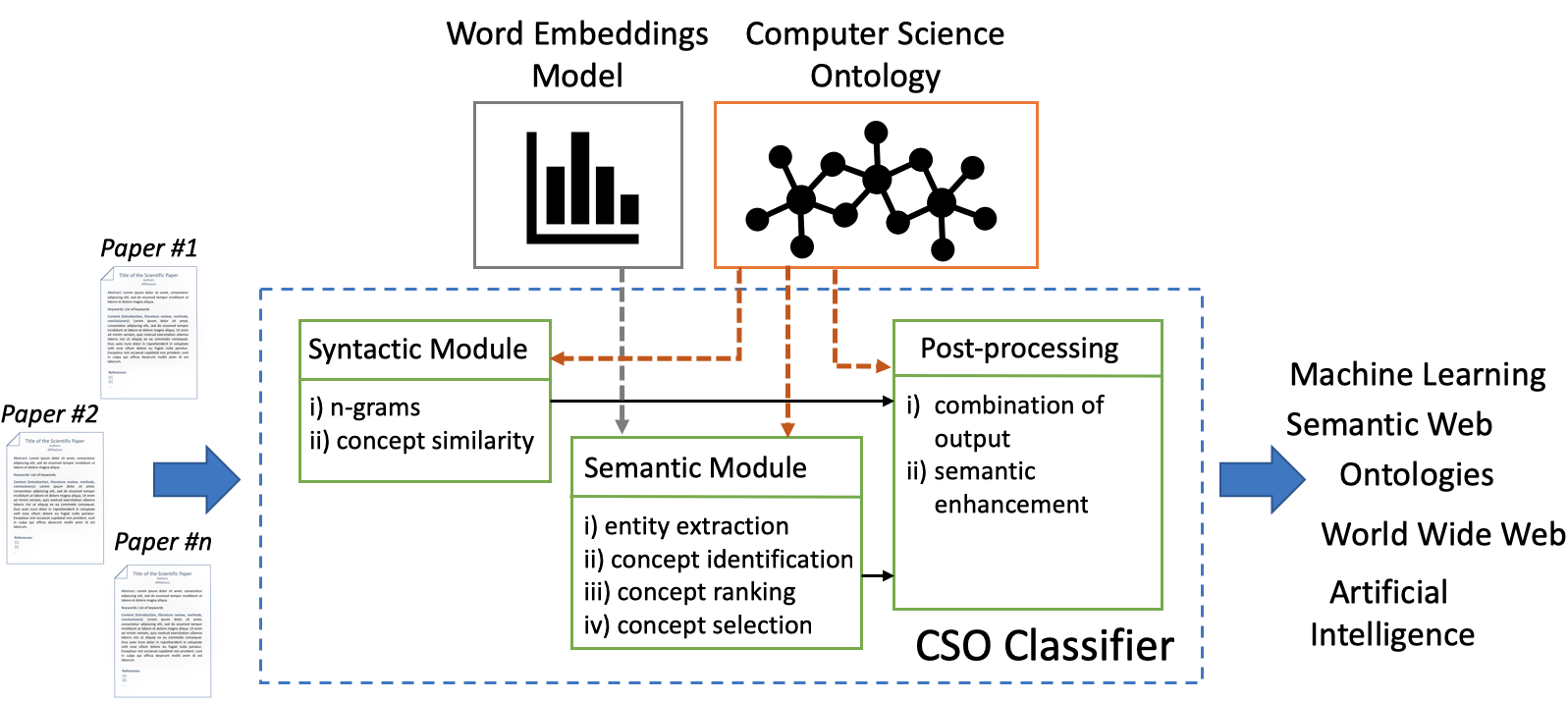
New release: CSO Classifier v2.1
We are pleased to announce that we recently created a new release of the CSO Classifier (v2.1), an application for automatically classifying research papers according to the Computer Science Ontology (CSO). Recently, we have been intensively working on improving its scalability, removing all its bottlenecks and making sure it could be run on large corpus. […]

CSO Classifier
Classifying research papers according to their research topics is an important task to improve their retrievability, assist the creation of smart analytics, and support a variety of approaches for analysing and making sense of the research environment. In this page, we present the CSO Classifier, a new unsupervised approach for automatically classifying research papers according to the Computer Science Ontology (CSO), a comprehensive ontology of research areas in the field of Computer Science.
Awesome Scholarly Data Analysis
Awesome Scholarly Data Analysis is a curated collection of resources that can support Scholarly Data analytics. This list ranges from: Datasets, which includes different corpora of papers, citations, authors and others, as well as taxonomies and ontologies of research concepts; Tools for collecting and classifying research papers, information extraction, and visualization; and Venues, Summer Schools, […]
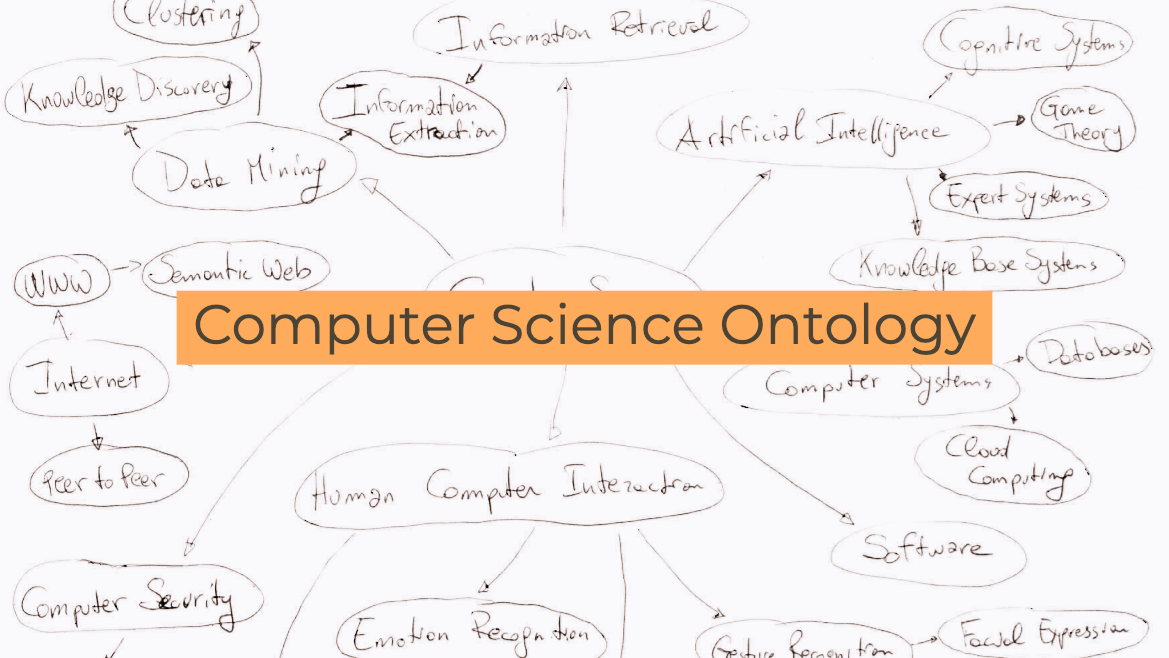
Computer Science Ontology
The Computer Science Ontology is a large-scale ontology of research areas that was automatically generated using the Klink-2 algorithm on a dataset of about 16 million publications, mainly in the field of Computer Science. In the rest of the paper, we will refer to this corpus as the Rexplore dataset.
The current version of CSO includes 14,164 topics and 162,121 semantic relationships. The main root is Computer Science; however, the ontology includes also a few secondary roots, such as Linguistics, Geometry, Semantics, and so on.
CSO presents two main advantages over manually crafted categorisations used in Computer Science (e.g., 2012 ACM Classification, Microsoft Academic Search Classification). First, it can characterise higher-level research areas by means of hundreds of sub-topics and related terms, which enables to map very specific terms to higher-level research areas. Secondly, it can be easily updated by running Klink-2 on a set of new publications.
Are citation networks really acyclic?
Simple answer: no. However, before getting into a more detailed answer, allow me to briefly introduce the concept of citation networks, then I will describe why citation networks cannot be considered acyclic anymore. In the scholarly domain, citation networks is an information network in which each node represents a scientific paper and a link between […]

Invited Talk – Early detection of Research Topics
On 2nd of August 2018, I have been invited by Boris Veytsman, Principal Research Scientist at Chan Zuckerberg Initiative (formerly Meta), to give a talk about my PhD work. Differently from my previous talk to the ORNL group, I had the opportunity to describe my doctoral work more comprehensively. More specifically, I initially showed what is available […]

Invited Talk – AUGUR: Forecasting the Emergence of New Research Topics
On 30th Jul 2018, I have been invited from Dasha Herrmannova, former PhD student at the KMi, to give a talk at the “Machine Learning and Graph Mining for Big Scholarly Data” workshop organised for the Computational Data Analytics Group at Oak Ridge National Laboratory (ORNL). In this talk, named “AUGUR: Forecasting the Emergence of New […]