
Smart Topic Miner (STM) is a web application which uses Semantic Web technologies to classify scholarly publications on the basis of Computer Science Ontology (CSO), a very large automatically generated ontology of research areas. STM was developed to support the Springer Nature Computer Science editorial team in classifying proceedings in the LNCS family. It […]
Category: Data Mining
Ontology Forecasting in Scientific Literature: Semantic Concepts Prediction based on Innovation-Adoption Priors
“Ontology Forecasting in Scientific Literature: Semantic Concepts Prediction based on Innovation-Adoption Priors” is a peer-reviewed paper presented on Tuesday 22nd November 2016 at the “Entity detection, matching and evolution” session at the 20th International Conference on Knowledge Engineering and Knowledge Management, Bologna, Italy Authors: Amparo Elizabeth Cano-Basave, Francesco Osborne and Angelo Antonio Salatino Abstract: The […]
Smart Topic Miner: Supporting Springer Nature Editors with Semantic Web Technologies
“Smart Topic Miner: Supporting Springer Nature Editors with Semantic Web Technologies” is poster paper presented at the Poster and Demo session [D45] on Wednesday 19th October 2016 at the 15th International Semantic Web Conference in Kobe, Japan Authors: Francesco Osborne, Angelo Antonio Salatino, Aliaksandr Birukou and Enrico Motta Abstract: Academic publishers, such as Springer Nature, annotate scholarly products […]
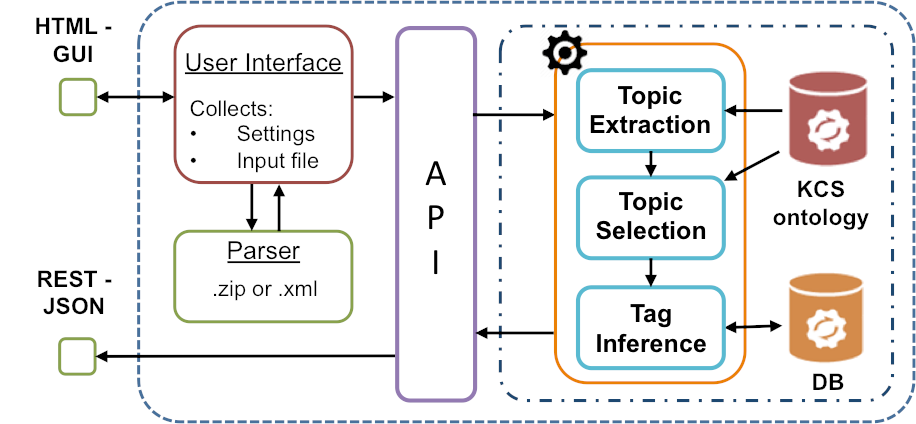
Automatic Classification of Springer Nature Proceedings with Smart Topic Miner
“Automatic Classification of Springer Nature Proceedings with Smart Topic Miner” is conference paper presented on Friday 21st October 2016 at the 15th International Semantic Web Conference in Kobe, Japan Authors: Francesco Osborne, Angelo Antonio Salatino, Aliaksandr Birukou and Enrico Motta Abstract: The process of classifying scholarly outputs is crucial to ensure timely access to knowledge. However, this […]
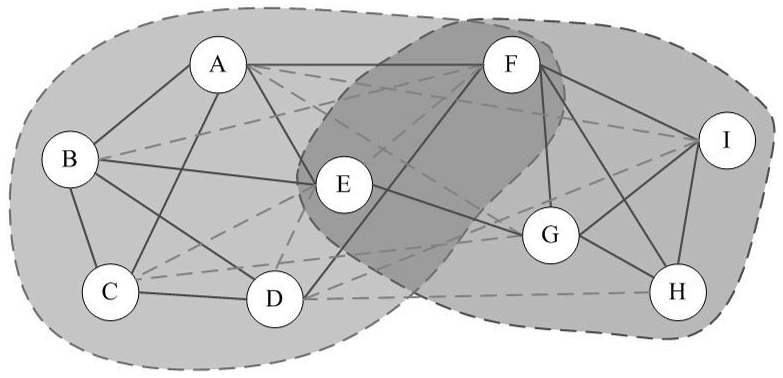
Clique Percolation Method in R: a fast implementation
Clique Percolation Method (CPM) is an algorithm for finding overlapping communities within networks, introduced by Palla et al. (2005, see references). This implementation in R, firstly detects communities of size k, then creates a clique graph. Each community will be represented by each connected component in the clique graph. Algorithm The algorithm performs the following […]

MK:SMART – Garden Monitor
I joined the project in March 2016 until September 2016, as Project Officer. My activities in this project involved setting up a network of sensors linked to MK Smart Data Hub. These sensors monitor the soil moisture of our users in a trial period, so that we could perform the evaluation of the following technology: Unnecessary […]

Advances Towards Early Detection of Research Topics
Acknowledging new trends in the research environment is important for many stakeholders, such as researchers, institutional funding bodies, academic publishers, and companies. In particular, being able to identify them as soon as possible can bring an important strategical advantage. A trend is usually defined as the general direction in which something is evolving. It is […]
Italian translation of official RStudio cheatsheets
I recently joined the community of RStudio, which is an Integrated Development Environment (IDE) for R (an open source statistical language to make sense of data). My contribution is providing the Italian Translation of their cheatsheet (Schede di Riferimento).
Tech Report: Early Detection and Forecasting of Research Trends
This is the First Year Probation Report submitted for the registration to the degree of Doctor of Philosophy at the Open University. Abstract Identifying and forecasting research trends is of critical importance for a variety of stakeholders, including researchers, academic publishers, institutional funding bodies, companies operating in the innovation space and others.
Advanced classification of Alzheimer’s disease and healthy subjects based on EEG markers
Authors: Vitoantonio Bevilacqua, Angelo Antonio Salatino, Carlo Di Leo, Giacomo Tattoli, Domenico Buongiorno, Domenico Signorile, Claudio Babiloni, Claudio Del Percio, Antonio Ivano Triggiani, Loreto Gesualdo Abstract: In this study, we compared several classifiers for the supervised distinction between normal elderly and Alzheimer’s disease individuals, based on resting state electroencephalographic markers, age, gender and education.